
- USD ЦБ 03.12 30.8099 -0.0387
- EUR ЦБ 03.12 41.4824 -0.0244
|
Краснодар:
|
погода |
21
48
апреля
15
вторник,
Курсы
Индексы
- DJIA 03.12 12019.4 -0.01
- NASD 03.12 2626.93 0.03
- RTS 03.12 1545.57 -0.07
ГОСТ Р 51294.6-2000
(ИСО/МЭК 16023-2000)
Группа П85
ГОСУДАРСТВЕННЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Автоматическая идентификация
КОДИРОВАНИЕ ШТРИХОВОЕ
Спецификация символики MaxiCode (Максикод)
Automatic identification. Bar coding. Symbology specification - MaxiCode
ОКС 35.040
ОКСТУ 4000
Дата введения 2001-07-01
Предисловие
1 РАЗРАБОТАН Ассоциацией автоматической идентификации ЮНИСКАН/ EAN РОССИЯ/ AIM РОССИЯ совместно с ООО "Интеркод"
ВНЕСЕН Техническим комитетом по стандартизации ТК 355 "Автоматическая идентификация"
2 ПРИНЯТ И ВВЕДЕН В ДЕЙСТВИЕ Постановлением Госстандарта России от 27 декабря 2000 г. N 426-ст
3 Настоящий стандарт представляет собой аутентичный текст международного стандарта ИСО/МЭК 16023-2000 "Информационная технология. Международная спецификация символики MaxiCode", за исключением разделов 2 и 3, приложений М, N и Р, рисунка L.1
4 ВВЕДЕН ВПЕРВЫЕ
Введение
MaxiCode (Максикод) - это матричная символика фиксированного размера, состоящая из смещенных строк шестиугольных модулей, окружающих уникальный шаблон поиска.
Производителям оборудования и пользователям технологии штрихового кодирования требуются общедоступные стандартные спецификации символик, к которым они могли бы обращаться при разработке оборудования и стандартов, регламентирующих применение этих символик. Настоящий стандарт регламентирует одну из таких спецификаций символик.
1 Область применения
Настоящий стандарт устанавливает требования к символике MaxiCode (Максикод), ее показателям, кодированию знаков данных, форматам символа, размерам, качеству печати, правилам исправления ошибок, алгоритму декодирования и задаваемым параметрам применения.
2 Нормативные ссылки
В настоящем стандарте использованы ссылки на следующие стандарты:
ГОСТ 7.67-94 (ИСО 3166-88) Система стандартов по информации, библиотечному и издательскому делу. Коды названий стран
ГОСТ 25532-89 Приборы с переносом заряда фоточувствительные. Термины и определения
ГОСТ 27463-87 Системы обработки информации. 7-битные кодированные наборы символов
ГОСТ 27465-87 Системы обработки информации. Символы. Классификация, наименование и обозначение
ГОСТ Р 34.303-92 (ИСО 4873-86) Информационная технология. Наборы 8-битных кодированных символов. 8-битный код обмена и обработки информации
ГОСТ Р 51294.1-99 Автоматическая идентификация. Кодирование штриховое. Идентификаторы символик
ГОСТ Р 51294.3-99 Автоматическая идентификация. Кодирование штриховое. Термины и определения
ИСО 646-91 Информационная технология. 7-битный кодированный набор знаков ИСО для обмена информацией
ИСО 8859-1-98 Обработка информации. Наборы 8-битных однобайтовых кодированных графических символов. Часть 1. Латинский алфавит N 1
ИСО 8859-5-99 Обработка информации. Наборы 8-битных однобайтовых кодированных графических символов. Часть 5. Латинский алфавит/кирилловский алфавит
Примечание - Международные стандарты - во ВНИИКИ Госстандарта России.
3 Определения и обозначения
3.1 Определения
В настоящем стандарте применяют термины по ГОСТ Р 51294.3, а также следующие термины с соответствующими определениями:
3.1.1 индикатор режима (Mode Indicator): Группа модулей в символе MaxiCode, используемая для определения структуры символа, например для установления уровня коррекции ошибки в символе.
3.1.2 интерпретация расширенного канала (ECl-Extended Channel Interpretation): Протокол, используемый некоторыми символиками, позволяющий интерпретировать исходящий поток данных в соответствии с набором знаков, отличным от набора знаков по умолчанию.
3.1.3 фоточувствительный прибор с зарядовой связью (ФПЗС): По ГОСТ 25532.
3.2 Обозначения
В настоящем стандарте применяют следующие обозначения:
![]() - кодовое слово;
- кодовое слово;
![]() - расстояние по вертикали от центра модуля в верхней строке до центра модуля в нижней строке;
- расстояние по вертикали от центра модуля в верхней строке до центра модуля в нижней строке;
![]() - расстояние от центра крайнего левого модуля до центра крайнего правого модуля в верхней строке;
- расстояние от центра крайнего левого модуля до центра крайнего правого модуля в верхней строке;
![]() - знак сообщения;
- знак сообщения;
![]() - общее количество кодовых слов данных;
- общее количество кодовых слов данных;
![]() - знак символа;
- знак символа;
![]() - высота модуля по вертикали;
- высота модуля по вертикали;
![]() - расстояние между центрами соседних модулей;
- расстояние между центрами соседних модулей;
![]() - ширина модуля по горизонтали;
- ширина модуля по горизонтали;
![]() - расстояние по вертикали от центральной линии модуля одной строки до центральной линии модуля соседней строки;
- расстояние по вертикали от центральной линии модуля одной строки до центральной линии модуля соседней строки;
![]() - целая часть оператора деления;
- целая часть оператора деления;
![]() - целая часть остатка от деления.
- целая часть остатка от деления.
4.1 Показатели символики
4.1.1 Основные показатели
К основным показателям матричной символики MaxiCode относят:
a) набор кодируемых знаков:
1) набор знаков по умолчанию позволяет закодировать 256 знаков:
знаки с десятичными целочисленными значениями от 0 до 127 в соответствии с ИСО 646*, т.е. все 128 знаков указанной версии КОИ-7;
____________
* Версия 7-битного кодированного набора знаков для обмена и обработки информации по ИСО 646 соответствует набору С0 ссылочной версии КОИ-7 Н0 по ГОСТ 27463-87 и набору Г0 версии КОИ-8 В1 по ГОСТ Р 34.303. В международном стандарте ИСО/МЭК 16023 указанная версия обозначена как ASCII по [1] и отмечено, что он эквивалентен ИСО 646.
знаки с десятичными значениями от 128 до 255 в соответствии с ИСО 8859-1;
2) цифровое уплотнение позволяет компоновать 9 цифр в шесть кодовых слов;
3) присутствуют различные управляющие знаки символики для переключения кода и других целей управления;
b) набор кодовых слов:
1) набор кодовых слов с 64 (2![]() ) значениями используют как промежуточный уровень кодирования между знаками данных и знаками символа. Кодовые слова являются основой для расчетов коррекции ошибок;
) значениями используют как промежуточный уровень кодирования между знаками данных и знаками символа. Кодовые слова являются основой для расчетов коррекции ошибок;
2) кодовые слова имеют значения от 0 до 63; в двоичном представлении - от 000000 до 111111. Внутри каждого знака символа бит старшего порядка - модуль с наименьшим номером, как показано на рисунках 1 и 5;
c) представление кодовых слов в символе MaxiCode:
1) каждое кодовое слово представлено шестью модулями шестиугольной формы;
2) информация в каждом модуле представлена в двоичном разряде. Темный модуль - это единица, а светлый модуль - нуль;
3) обычно шесть модулей составляют в три строки по два модуля - справа налево, сверху вниз. На рисунке 1 показаны модули типичного знака символа;
4) знаки символа от 1 до 9 и от 137 до 144 составлены, как показано на рисунке 4 (особый состав этих знаков обусловлен структурой символа MaxiCode);
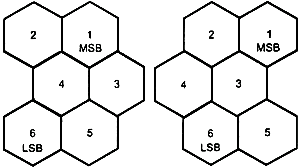
MSB - бит старшего порядка,
LSB - бит младшего порядка
Рисунок 1 - Модули типичного знака символа в символе MaxiCode
d) размер символа:
1) любой символ MaxiCode имеет фиксированный размер. Он состоит из 884 шестиугольных модулей, расположенных в 33 строки, окружающих центральный шаблон поиска. В каждой строке должно быть не более 30 модулей;
2) каждый символ, включая свободную зону, имеет фиксированный номинальный размер:
28,14 мм по ширине и 26,91 мм по высоте;
3) 864 модуля (144 знака символа) используют для кодирования данных и коррекции ошибки. Два модуля не используют;
4) часть, не содержащая данных:
- 18 модулей на символ штрихового кода для ориентации;
- эквивалентная 90 модулям для шаблона поиска;
e) максимальная емкость данных:
1) алфавитно-цифровых знаков - 93;
2) цифровых знаков - 138;
f) коррекция ошибок - 50 или 66 кодовых слов на символ MaxiCode;
g) тип кода - матричный;
h) независимость ориентации - присутствует.
4.1.2 Дополнительные показатели
К дополнительным показателям MaxiCode относят:
обязательные показатели:
a) шаблон поиска - центральный уникальный шаблон поиска, содержащийся в символах MaxiCode, состоящий из трех темных концентрических колец. Шаблон поиска используют для определения местонахождения символа MaxiCode в поле обзора (4.2.1.1). Наличие шаблона поиска и фиксированного размера символа позволяет использовать символику MaxiCode в применениях, где требуется высокая скорость сканирования;
b) исправление ошибок - кодовые слова коррекции ошибок, содержащиеся в символах MaxiCode, составленные на основе алгоритма исправления ошибок Рида-Соломона, которые могут быть использованы не только для обнаружения ошибок, но и для исправления неправильно декодированных или пропущенных кодовых слов (4.5.1). Пользователь может выбрать один из двух уровней коррекции ошибок;
c) режимы - механизм, допускающий использование различных структур символа. Различают семь режимов (включая два устаревших по 4.8);
необязательные показатели:
d) интерпретации расширенного канала (Extended Channel Interpretation - ECI (ИСиАй)) - механизм, позволяющий представлять знаки из других наборов (например кирилловский алфавит, арабский, греческий, иврит), а также другие интерпретации данных или специальные отраслевые требования;
e) структурированное соединение - свойство, позволяющее представлять файлы данных в виде нескольких (до восьми) символов MaxiCode. Первоначальные данные могут быть безошибочно воссозданы независимо от последовательности, в которой были считаны символы (4.9).
4.2 Описание символа
4.2.1 Структура символа
Каждый символ MaxiCode состоит из центрального шаблона поиска, окруженного массивом 33 смещенных строк шестиугольных модулей. Длина каждой строки символа варьируется от 30 до 29 модулей. С четырех сторон символ должен быть окружен свободными зонами. На рисунке 2 представлен символ MaxiCode (с визуальным представлением).

"THIS IS A 93 CHARACTER CODE SET A MESSAGE THAT FILLS A MODE 4,
UNAPPENDED, MAXICODE SYMBOL..."
Рисунок 2 - Символ MaxiCode (фактический размер)
4.2.1.1 Шаблон поиска
Шаблон поиска состоит из трех темных концентрических колец и трех внутренних светлых областей, центрированных относительно виртуального модуля, установленного в 4.11.4. На рисунке 3 показан шаблон поиска относительно примыкающей комбинации модулей.

В - черные или темные модули шаблона ориентации;![]() - белые или светлые модули шаблона ориентации;
- белые или светлые модули шаблона ориентации;
![]() - виртуальный шестиугольник
- виртуальный шестиугольник
Рисунок 3 - Структура символа MaxiCode
(с шаблоном поиска и модулями ориентации)
4.2.1.2 Шаблоны ориентации
Ориентация информации осуществляется за счет шести шаблонов, состоящих из трех модулей. Точное размещение шаблонов ориентации показано на рисунках 3-5.
4.2.2 Знак символа и последовательность модулей
Символ MaxiCode состоит из 144 знаков символа в первичном и вторичном сообщениях, расположенных в следующей последовательности:
а) знаки символа первичного сообщения (с 1-го по 20-й) расположены вокруг шаблона поиска, как показано на рисунке 4. Знаки символа вторичного сообщения (с 21-го по 144-й) расположены в особой конфигурации*, которая начинается в верхнем левом углу, продолжается слева направо в первой строке, справа налево во второй строке и т.д. (рисунок 4);
______________
* Такая конфигурация, нередко используемая в информационных технологиях, называется бострофедонической по названию текстов древних манускриптов с характерным расположением знаков.
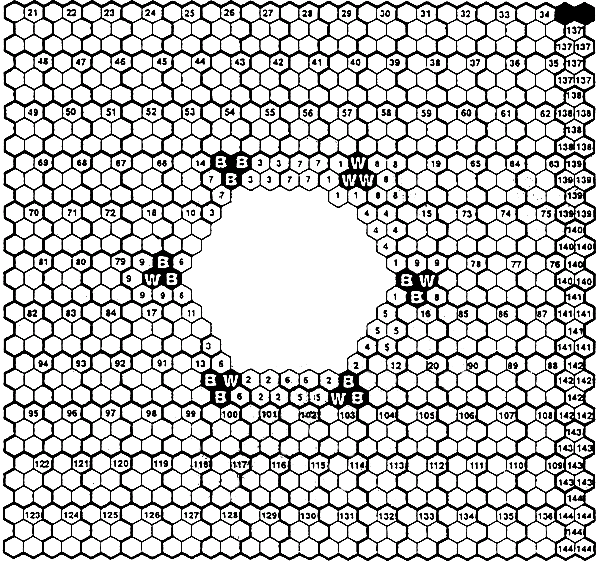
Рисунок 4 - Последовательность знаков символа MaxiCode
b) каждый шестиугольный модуль пронумерован. На рисунке 5 приведена последовательность нумерации шестиугольных модулей в символе. Обычно шестиугольные модули знака символа являются непрерывными и имеют нумерацию внутри знака символа справа налево и сверху вниз. В любом случае в знаке символа модуль с наименьшим номером - бит старшего порядка (рисунок 1), модуль ![]() - это
- это ![]() -й бит знака символа
-й бит знака символа ![]() от
от ![]() =1
=1![]() (бит старшего порядка) до
(бит старшего порядка) до ![]() =6
=6 ![]() (бит младшего порядка), где
(бит младшего порядка), где
![]() ,
,
![]() ;
;
с) модули с 1-го по 120-й, т.е. 20 знаков символа, должны содержать информацию первичного сообщения, включая данные, информацию о коррекции ошибки и о режиме. Модули с 121-го по 864-й, т.е. 124 знака символа, должны содержать информацию вторичного сообщения.
Два крайних правых модуля верхней строки не используют (рисунок 5). Они должны быть закодированы, как темные модули.

4.3 Процедуры основного кодирования
Для преобразования данных в закодированную форму, представленную в виде символа MaxiCode, необходимы следующие этапы преобразования данных:
1 - для транспортных применений определяют, является ли структурированное сообщение носителя подходящим, и к первичному сообщению применяют специальные правила кодирования;
2 - в MaxiCode можно закодировать данные из набора 256 знаков, которые должны быть представлены в виде потока данных, считываемого слева направо;
3 - каждый знак данных переводят в кодовое слово (0-63). Для переключения между различными подмножествами наборов знаков используют дополнительные кодовые слова;
4 - пользователь или разработчик конкретного применения выбирает один из двух уровней коррекции ошибки;
5 - для обеспечения необходимой размерности символа используют знаки Pad (ЗАПОЛНИТЕЛЬ);
6 - поток кодовых слов делят на первичное и вторичное сообщения;
7 - для первичного и вторичного сообщений генерируются кодовые слова коррекции ошибок. В результате этой операции поток кодовых слов расширяется за счет кодовых слов коррекции ошибок (50 или 66);
8 - поток кодовых слов преобразуется в два битовых потока для первичного и вторичного сообщений;
9 - первичный и вторичный битовые потоки бит за битом преобразуют в последовательность шестиугольных модулей символа MaxiCode (рисунок 5).
4.4 Назначение знаков
Набор из 64 кодовых слов в MaxiCode используют для кодирования до 256 различных знаков, что предоставляет возможность уплотнить цифры и кодировать сообщения с особой структурой (в соответствии с 4.7.3 для описания режимов 2 и 3).
Установлены пять кодируемых наборов (от А до Е) (Code Set A - Code Set E) для кодирования 256 знаков. В приложении А приведена совокупность знаков и расположение знаков в пяти кодируемых наборах (от А до Е). Знаки сгруппированы в кодируемых наборах в соответствии с вероятным использованием. Кодируемый набор A (Code Set А) содержит наиболее часто используемые знаки; во многих применениях отсутствует необходимость переключения из этого основного набора знаков в другие. Для выбора других знаков данных необходимо использовать знаки Latch (ФИКСАТОР) и Shift (РЕГИСТР) (4.4.4.1-4.4.4.5).
4.4.1 Представление кодовых слов
Кодовые слова или значения знаков символа в MaxiCode представлены в диапазоне от 0 до 63. Двоичный эквивалент кодового слова (т.е. от 000000 до 111111) должен быть непосредственно представлен в символе MaxiCode в виде 6 шестиугольных модулей.
Обычно в символе MaxiCode последовательность модулей кодового слова представляют в соответствии с рисунком 1, а все данные должны соответствовать последовательности комбинации модулей, приведенной на рисунке 5.
4.4.2 Интерпретация знаков по умолчанию
Интерпретация знаков по умолчанию для знаков версии КОИ-7 с целочисленными значениями от 0 до 127 должна соответствовать ИСО 646*. Интерпретация знаков по умолчанию для знаков версии КОИ-8 с целочисленными значениями от 128 до 255 должна соответствовать ИСО 8859-1. Графическое представление знаков данных, указанных в настоящем документе, соответствует интерпретации по умолчанию. Эта интерпретация может быть изменена при использовании управляющей последовательности знаков интерпретации расширенного канала (ECI) в соответствии с 4.6. Интерпретация по умолчанию соответствует ECI 000003.
________________
* В ИСО/МЭК 16093 дана ссылка на [1], эквивалентный ИСО 646.
4.4.3 Кодируемые наборы
4.4.3.1 Кодируемый набор A (Code Set A)
Кодируемый набор А является кодируемым набором знаков по умолчанию в начале каждого символа MaxiCode.
Кодируемый набор А содержит все типовые прописные буквы латинского алфавита, цифры от 0 до 9, 15 стандартных специальных графических знаков (знаков пунктуации), знак Space (ПРОБЕЛ) и управляющие знаки [CR] ([BKC]), [FS] ([PФ]), [GS] ([РГ]) и [RS] ([РЗ])*, используемые в синтаксисе данных, а также в дополнение к этому восемь управляющих знаков символики.
________________
* В скобках в дополнение к международным обозначениям знаков указаны русские обозначения по ГОСТ 27465-87.
4.4.3.2 Кодируемый набор В (Code Set В)
Кодируемый набор В содержит строчные буквы латинского алфавита и дополнительные специальные графические знаки (знаки пунктуации), а также в дополнение к этому управляющие знаки FS (РФ), GS (РГ), RS (РЗ) и DEL (ЗБ)* и 12 управляющих знаков символики.
________________
* В скобках в дополнение к международным обозначениям знаков указаны русские обозначения по ГОСТ 27465-87.
4.4.3.3 Кодируемый набор С (Code Set С)
Кодируемый набор С содержит прописные буквы различных алфавитов и дополнительные специальные графические знаки (знаки пунктуации и другие). Он также содержит управляющие знаки FS (РФ), GS (РГ), RS (РЗ)*, используемые для синтаксиса данных и 10 знаков версии КОИ-8 (с десятичными значениями от 128 до 137), не имеющих графического представления в ИСО 8859-1, а также в дополнение к этому семь управляющих знаков символики.
________________
* В ИСО/МЭК 16093 дана ссылка на [1], эквивалентный ИСО 646.
4.4.3.4 Кодируемый набор D (Code Set D)
Кодируемый набор D содержит строчные буквы различных алфавитов и дополнительные специальные графические знаки (знаки пунктуации). Он также содержит управляющие знаки FS (РФ), GS (РГ), RS (РЗ)*, используемые для синтаксиса данных, и 11 знаков версии КОИ-8 (с десятичными значениями от 138 до 148), не имеющих графического представления в ИСО 8859-1, а также в дополнение к этому семь управляющих знаков символики.
________________
* В скобках в дополнение к международным обозначениям знаков указаны русские обозначения по ГОСТ 27465-87.
4.4.3.5 Кодируемый набор Е (Code Set E)
Кодируемый набор Е содержит 31 управляющий знак версии КОИ-7, индикаторы валют и другие специальные графические знаки. Он содержит 11 знаков версии КОИ-8 (с десятичными значениями от 149 до 159), не имеющих графического представления в ИСО 8859-1, а также в дополнение к этому девять управляющих знаков символики.
4.4.4 Управляющие знаки символики (Symbology Control Characters)
MaxiCode содержит 15 управляющих знаков символики - специальных знаков, не являющихся знаками данных и не имеющих эквивалента среди знаков КОИ-7. Эти знаки используют для указания команды декодеру на выполнение некоторых функций или передачу специальных данных главному компьютеру в соответствии с 4.4.4.1-4.4.4.8. В таблице 1 приведен полный перечень управляющих знаков символики. В приложении F приведено руководство по оптимальному использованию знаков Latch (ФИКСАТОР), Shift (РЕГИСТР) и Lock-In (БЛОКИРОВКА).
Таблица 1 - Управляющие знаки символики MaxiCode
|
Международное (русское) наименование функции и назначение |
Международное (русское) обозначение |
Значение кодового слова в кодируемом наборе |
Пункт настоящего стандарта | ||||
|
|
|
А |
В |
С |
D |
Е |
|
|
Latch (ФИКСАТОР): служит для переключения на новый кодируемый набор и работе в нем до следующего переключения |
Latch А (ФИКСАТОР А) |
|
63 |
58 |
58 |
58 |
4.4.4.1 |
|
|
Latch В (ФИКСАТОР В) |
63 |
|
63 |
63 |
63 |
|
|
Shift (РЕГИСТР): служит для переключения на другой кодируемый набор для одного знака и возврата обратно |
Shift А (РЕГИСТР А) |
|
59 |
|
|
|
4.4.4.2 |
|
|
Shift В (РЕГИСТР В) |
59 |
|
|
|
|
|
|
|
Shift С (РЕГИСТР С) |
60 |
60 |
|
60 |
60 |
|
|
|
Shift D (РЕГИСТР D) |
61 |
61 |
61 |
|
61 |
|
|
|
Shift Е (РЕГИСТР Е) |
62 |
62 |
62 |
62 |
|
|
|
Lock-In (БЛОКИРОВКА): расширяет возможности знака Shift (РЕГИСТР), позволяет использовать знак Shift (РЕГИСТР) так же, как и знак Latch (ФИКСАТОР), позволяет работать в новом кодируемом наборе до следующего переключения |
Lock-In С |
|
|
60 |
|
|
4.4.4.3 |
|
|
Lock-In D |
|
|
|
61 |
|
|
|
|
Lock-In Е |
|
|
|
|
62 |
|
|
Double Shift (РЕГИСТР НА ДВА): служит для переключения на новый кодируемый набор для двух знаков |
2 Shift A |
|
56 |
|
|
|
4.4.4.4 |
|
Triple Shift (РЕГИСТР НА ТРИ): служит для переключения на новый кодируемый набор для трех знаков |
3 Shift A |
|
57 |
|
|
|
4.4.4.5 |
|
Numeric Shift (ЦИФРОВОЙ РЕГИСТР): позволяет эффективно уплотнять цепочки цифр |
NS (ЦР) |
31 |
31 |
31 |
31 |
31 |
4.4.4.6 |
|
Интерпретация расширенного канала - позволяет перейти к новой интерпретации расширенного канала (ECI) |
ECI (ИРК) |
27 |
27 |
27 |
27 |
27 |
4.4.4.7 |
|
Pad (ЗАПОЛНИТЕЛЬ) - служит для заполнения символа и для обозначения структурированного соединения |
33 |
33 |
|
|
|
28 |
4.4.4.8 |
|
|
|
|
55 |
|
|
29 |
|
|
|
|
|
58 |
|
|
|
|
|
Примечание - Русские наименования знаков в графе 1 - в соответствии с приложением М. | |||||||
4.4.4.1 Знаки Latch (ФИКСАТОР)
Знак Latch (ФИКСАТОР) может использоваться для переключения с ранее определенного набора знаков на новый набор знаков. Все кодовые слова, следующие за знаком Latch (ФИКСАТОР), должны быть интерпретированы в соответствии с новым набором знаков. Переключение действует до следующего знака Latch (ФИКСАТОР) или знака Shift (РЕГИСТР).
Знак Latch (ФИКСАТОР) присутствует во всех кодируемых наборах, но используется только для переключения на кодируемые наборы А или В.
4.4.4.2 Знаки Shift (РЕГИСТР)
Знак Shift (РЕГИСТР) используют для переключения от ранее определенного набора знаков к новому набору знаков для одного знака, следующего за знаком Shift (РЕГИСТР). Следующие знаки кодируют в соответствии с набором, определенным до знака Shift (РЕГИСТР).
Знак Shift (РЕГИСТР) присутствует во всех наборах знаков. Из кодируемых наборов А или В можно переключиться на любой другой.
4.4.4.3 Знаки Lock-In (БЛОКИРОВКА)
Знак Lock-In, следующий за знаком Shift (РЕГИСТР), для того же набора знаков действует так же, как и знак Latch (ФИКСАТОР). Выбранный набор знаков действует до последующего использования знака Latch (ФИКСАТОР).
4.4.4.4 Знак Double Shift (РЕГИСТР НА ДВА)
Знак Double Shift (обозначается [2 Shift A] ([2 РЕГИСТР А])) действует для переключения с набора знаков В на набор знаков А для двух знаков, следующих за знаком [2 Shift А]. Последующие знаки должны вернуться к кодируемому набору В.
4.4.4.5 Знак Triple Shift (РЕГИСТР НА ТРИ)
Знак Triple Shift (обозначается [3 SHIFT A] ([3 РЕГИСТР А])) действует для переключения с набора знаков В на набор знаков А для трех знаков, следующих за знаком [3 SHIFT А]. Последующие знаки должны вернуться к кодируемому набору В.
4.4.4.6 Знак Numeric Shift (ЦИФРОВОЙ РЕГИСТР)
Знак Numeric Shift (ЦИФРОВОЙ РЕГИСТР) позволяет кодировать цепочки из 9 цифр в 6 кодовых словах. Знак Numeric Shift (обозначается [NS] ([ЦР])) указывает, что следующие 5 кодовых слов, эквивалентные 30 битам, кодируют 9 цифровых разрядов в двоичном формате. Последующие знаки кодируют в соответствии с кодируемым набором, определенным до знака Numeric Shift (ЦИФРОВОЙ РЕГИСТР). Для цифровых цепочек длиннее 9 цифр можно комбинировать цифровое уплотнение с использованием знаков Numeric Shift (ЦИФРОВОЙ РЕГИСТР) с обычным кодированием. В приложении F приведены более подробные рекомендации по применению знака Numeric Shift (ЦИФРОВОЙ РЕГИСТР) для цифровых цепочек переменной длины.
4.4.4.7 Знак Extended Channel Interpretation (ИНТЕРПРЕТАЦИЯ РАСШИРЕННОГО КАНАЛА)
Знак Extended Channel Interpretation (обозначается [ECI] ([ИРК])) используют для изменения интерпретации кодируемых данных, установленной по умолчанию. Протокол интерпретации расширенного канала является общим для ряда символик. Более полные требования к знаку приведены в 4.6.
За знаком [ECI] должны следовать один, два, три или четыре кодовых слова, идентифицирующие вызываемую интерпретацию. Новая интерпретация расширенного канала (ECI) остается неизменной либо до конца кодируемых данных, либо до использования следующего знака [ECI] для вызова другой интерпретации.
4.4.4.8 Знак Pad (ЗАПОЛНИТЕЛЬ)
Если знак [Pad] стоит в начальной позиции, то его используют для структурированного соединения (4.9); во всех остальных случаях знак [Pad] используют для заполнения незанятого объема данных в символе.
4.5 Рекомендации для пользователя по кодированию данных в символе MaxiCode
Символ MaxiCode состоит из фиксированного числа модулей и кодовых слов. 144 кодовых слова могут использоваться для кодирования режимов, данных, управляющих функций символики и исправления ошибок. Можно использовать структурированное соединение для объединения до восьми символов MaxiCode. Число параметров символики зависит от применения, включая уровень коррекции ошибки и режим. Другие параметры более тесно связаны с данными, включая использование определенных наборов знаков, необходимость соответствия данных определенным стандартам, регламентирующим применение MaxiCode, или синтаксису сообщений (например, EDIFACT (ЭДИФАКТ)) и степень переключения между кодируемыми наборами знаков. Кодирование символов MaxiCode должно производиться автоматически. В 4.5.5 и приложении G приведены общие рекомендации по кодированию данных с учетом емкости символа.
4.5.1 Выбор пользователем уровня коррекции ошибки
В символах MaxiCode может быть установлен один из двух уровней коррекции ошибки, которые определены в 4.10. В конкретном применении важно понимать различия между этими двумя уровнями: для них требуется различное количество кодовых слов, они используют разные уровни коррекции ошибки и выбираются в зависимости от выбранного режима. Основные параметры уровней коррекции ошибки приведены в таблице 2.
Таблица 2 - Параметры коррекции ошибок
|
Параметр |
Уровень коррекции ошибки | |
|
|
стандартный |
расширенный |
|
Общее число кодовых слов |
144 |
144 |
|
Число кодовых слов для кодирования данных |
93 |
77 |
|
Кодовое слово, используемое для определения режима |
1 |
1 |
|
Число кодовых слов для коррекции ошибки |
50 |
66 |
|
Число ошибочно декодированных кодовых слов, которые могут быть исправлены |
22 |
30 |
4.5.2 Выбор пользователем режима
Символы MaxiCode содержат пять режимов кодирования, которые установлены в 4.8. Обычно режимы используют для определения формата сообщения и уровня коррекции ошибки.
4.5.3 Выбор пользователем интерпретации расширенного канала (ECI)
Для выбора интерпретации расширенного канала с целью идентификации определенного кодируемого набора или интерпретации дополнительных специальных данных требуются дополнительные кодовые слова. Использование протокола интерпретации расширенного канала (4.6) позволяет кодировать данные алфавитов, отличных от латинского по ИСО 8859-1, поддерживаемого интерпретацией по умолчанию.
4.5.4 Выбор пользователем структурированного соединения
Для некоторых практических применений требуется, чтобы несколько символов MaxiCode были организованы в виде одного символа, либо фиксированного или наибольшего числа символов, либо достигали предела из восьми связанных символов. В 4.9 установлены требования к структурированному соединению. Предельное количество символов MaxiCode может быть установлено в конкретном применении. Для того, чтобы определить символ MaxiCode как часть структурированного соединения, необходимо два кодовых слова.
4.5.5 Оценка пользователем емкости для кодирования
Символы MaxiCode имеют ограничения по емкости данных (Таблица 2). Рекомендации по оценке пользователем емкости кодирования приведены в приложении G.
4.6 Интерпретация расширенного канала
Протокол интерпретации расширенного канала (протокол ECI) позволяет интерпретировать исходящий поток данных отлично от интерпретации набора знаков по умолчанию. Протокол ECI применяется также в ряде иных символик (например, PDF417, Data matrix, QR Code и др.).
MaxiCode поддерживает четыре типа интерпретаций:
a) международные наборы знаков (или кодовые страницы);
b) интерпретации общего назначения (кодирование и уплотнение);
c) интерпретации, определяемые пользователем для замкнутых систем;
d) управляющая информация для структурированного соединения в небуферизованном режиме.
Протокол ECI [3] позволяет последовательно определять значения байтов знаков перед печатью и после декодирования.
Протокол ECI идентифицируют шестизначным числом, которое кодируется в символе MaxiCode знаком [ECI] и следующими за ним кодовыми словами в количестве от одного до четырех.
Специфическую интерпретацию расширенного канала можно использовать в любом месте кодируемого сообщения при всех режимах кодирования, кроме символов в режимах 2 и 3 (4.6.1).
Интерпретация расширенного канала может быть использована только совместно с устройствами считывания, способными передавать идентификаторы символик. Устройства считывания, не способные передавать идентификаторы символик, не смогут передать данные, в символе которых содержится значение ECI. Исключение составляют случаи, когда значения ECI обрабатываются самим устройством считывания.
4.6.1 Интерпретация расширенного канала и режимы кодирования 2 и 3
Режимы кодирования 2 и 3 используют для кодирования в первичном сообщении структурированного сообщения носителя (4.8.3).
При использовании режимов кодирования 2 и 3 значения ECI могут располагаться только во вторичном сообщении.
4.6.2 Режимы кодирования и знаки [ECI]
Используемый режим кодирования строго определен 8-битными закодированными значениями данных и не зависит от действующей интерпретации расширенного канала. Например, последовательность знаков с десятичными значениями от 48 до 57 будет закодирована наиболее эффективно в цифровом режиме даже в том случае, если последовательность не интерпретируется как цифровая.
4.6.3 Кодирование интерпретаций расширенного канала в MaxiCode
Назначение интерпретации расширенного канала (ECI) вызывается при помощи кодового слова 27 - знака [ECI]. Для кодирования номера назначения ECI (ECI Assignment Number) используют от одного до четырех дополнительных кодовых слов. Правила кодирования определены в таблице 3.
Таблица 3 - Кодирование номера назначения ECI (ECI Assignment Number)
|
Значение номера назначения ECI |
Последовательность кодовых слов |
Значения кодовых слов |
|
От 000000 до 000031 |
|
[27][0bbbbb] |
|
" 000000 " 001023 |
|
127][10bbbb][bbbbbb] |
|
" 000000 " 032767 |
|
[27] [110bbb] [bbbbbb] [bbbbbb] |
|
" 000000 " 999999 |
|
[27] [1110bb] [bbbbbb] [bbbbbb] [bbbbbb] |
|
Примечание - b...b - это двоичное значение номера назначения ECI. | ||
Примечание - При декодировании двоичная комбинация кодового слова С1 (т.е. кодового слова, следующего за кодовым словом 27) определяет длину последовательности ECI. Количество битов со значением 1 перед первым нулевым битом определяет количество дополнительных кодовых слов, используемых для определения номера назначения ECI (ECI Assignment Number). Последовательность битов, следующая за первым нулевым битом, является номером ECI в двоичном представлении.
Номера назначения ECI (ECI Assignment Number) с наименьшими значениями могут быть закодированы различными способами, наиболее предпочтительным является кратчайший.
4.6.4. Интерпретации расширенного канала и структурированное соединение
Интерпретации расширенного канала могут кодироваться в любом месте сообщения как в единичном наборе символов, так и в наборе символов MaxiCode структурированного соединения, но не могут содержаться в первичных сообщениях для режимов 2 и 3. Любая вызванная интерпретация расширенного канала (ECI) должна действовать до окончания кодируемых данных или до начала следующей интерпретации расширенного канала (ECI). Таким образом, интерпретация в рамках одной ECI может охватить два и более символов.
4.6.5. Протокол после декодирования
Протокол передачи данных интерпретации расширенного канала (ECI) должен соответствовать 4.15.2. При использовании интерпретаций расширенного канала (ECI) идентификаторы символик (4.15.3) должны быть использованы полностью и соответствующий идентификатор символики должен быть передан в качестве префикса сообщения.
4.7. Структура сообщения
Символы MaxiCode делятся на первичное и вторичное сообщения, каждое из которых содержит данные и кодовые слова коррекции ошибки. Эти сообщения структурированы в соответствии с рисунком 6.
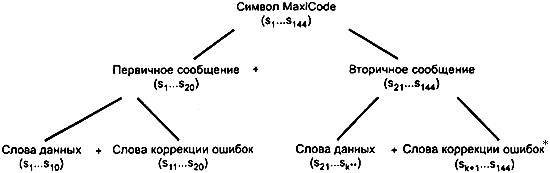
* Во вторичном сообщении кодовые слова коррекции ошибок вычисляют в четном и в нечетном подмножестве
** k=104 для стандартной коррекции ошибок, k=88 для расширенной коррекции ошибок
Рисунок 6 - Структура символа и обозначения знаков символа
4.7.1 Первичное сообщение
Первичное сообщение состоит из 20 знаков символа, которые обозначены на рисунке 4 от 1 (![]() ) до 20 (
) до 20 (![]() ) и представлены модулями от 1 до 120 на рисунке 5. При этом:
) и представлены модулями от 1 до 120 на рисунке 5. При этом:
10 знаков (от ![]() до
до ![]() ) используют для кодирования данных (включая режим символа),
) используют для кодирования данных (включая режим символа),
10 знаков (от ![]() до
до ![]() ) используют для коррекции ошибок.
) используют для коррекции ошибок.
Четыре бита младшего порядка знака символа ![]() ( (модули с 3-го по 6-й) кодируют режим (4.8). Другие два модуля в
( (модули с 3-го по 6-й) кодируют режим (4.8). Другие два модуля в ![]() должны быть равны нулю, если не являются частью структурированного сообщения носителя (приложение В). Расширенная коррекция ошибок (4.10.1) всегда применяется к первичному сообщению.
должны быть равны нулю, если не являются частью структурированного сообщения носителя (приложение В). Расширенная коррекция ошибок (4.10.1) всегда применяется к первичному сообщению.
В режимах 2 и 3 первичное сообщение представляет собой форматированное структурированное сообщение носителя, как установлено в приложении В. В режимах с 4-го по 6-й первичное сообщение содержит знак режима символа и девять знаков символа, которые начинают кодирование сообщения данных символа.
4.7.2 Вторичное сообщение
Вторичное сообщение состоит из 124 знаков символа, обозначенных на рисунке 4 от 21-го (![]() ) до 144-го (
) до 144-го (![]() ) и представленных на рисунке 5 модулями от 121 до 864. Ко вторичному сообщению можно применить один из двух уровней коррекции ошибок, как расширенную коррекцию ошибок РКО (Enhanced Error Correction - EEC), так и стандартную коррекцию ошибок СКО (Standard Error Correction - SEC) (согласно 4.10.2).
) и представленных на рисунке 5 модулями от 121 до 864. Ко вторичному сообщению можно применить один из двух уровней коррекции ошибок, как расширенную коррекцию ошибок РКО (Enhanced Error Correction - EEC), так и стандартную коррекцию ошибок СКО (Standard Error Correction - SEC) (согласно 4.10.2).
При расширенной коррекции ошибок (EEC):
68 знаков символа (от ![]() до
до ![]() ) используют для кодирования данных, а
) используют для кодирования данных, а
56 знаков символа (от ![]() до
до ![]() ) - для исправления ошибок.
) - для исправления ошибок.
При стандартной коррекции ошибок (SEC):
84 знака символа (от ![]() до
до ![]() ) используют для кодирования данных, а
) используют для кодирования данных, а
40 знаков символа (от ![]() до
до ![]() ) - для исправления ошибок.
) - для исправления ошибок.
В обоих случаях исправление ошибок для вторичного сообщения применяется в двух чередующихся подмножествах Рида-Соломона, обозначенных как четное и нечетное подмножества. Знаки символа с нечетными номерами ![]() ,
, ![]()
![]() ,...,
,..., ![]() входят в последовательность нечетного подмножества, а знаки символа с четными номерами
входят в последовательность нечетного подмножества, а знаки символа с четными номерами ![]() ,
, ![]() ,
, ![]() ,...,
,..., ![]() - в последовательность четного подмножества. В каждом подмножестве кодовые слова коррекции ошибок выводятся из кодовых слов данных в этом же подмножестве и, в конечном счете, обеспечивают исправление ошибок для кодовых слов данных в этом подмножестве.
- в последовательность четного подмножества. В каждом подмножестве кодовые слова коррекции ошибок выводятся из кодовых слов данных в этом же подмножестве и, в конечном счете, обеспечивают исправление ошибок для кодовых слов данных в этом подмножестве.
Знаки символа для данных во вторичном сообщении (предваряющиеся 9 знаками символа от первичного сообщения для режимов 4, 5 и 6) кодируют сообщение данных с использованием кодируемых наборов и управляющих знаков (4.4.3 и 4.4.4).
4.7.3 Структурирование данных
Изначально подлежащую кодированию цепочку сообщения с данными от ![]() до
до ![]() кодируют в последовательность 6-битовых кодовых слов от
кодируют в последовательность 6-битовых кодовых слов от ![]() до
до ![]() , с использованием кодируемых наборов знаков и управляющих знаков символики в соответствии с потребностями данного применения (4.4.3 и 4.4.4). За специальными правилами кодирования следуют назначение и класс служебных данных в структурированном сообщении носителя с цифровым (режим 2) или алфавитно-цифровым (режим 3) почтовым кодом (4.8.3 и приложение В). В приложении F приведены рекомендации по нахождению наиболее эффективного использования управляющих знаков символики.
, с использованием кодируемых наборов знаков и управляющих знаков символики в соответствии с потребностями данного применения (4.4.3 и 4.4.4). За специальными правилами кодирования следуют назначение и класс служебных данных в структурированном сообщении носителя с цифровым (режим 2) или алфавитно-цифровым (режим 3) почтовым кодом (4.8.3 и приложение В). В приложении F приведены рекомендации по нахождению наиболее эффективного использования управляющих знаков символики.
В режимах 2 и 3 кодовые слова сообщения с данными располагают исключительно во вторичном сообщении, начиная со знака символа 21. В режимах с 4-го по 6-й начальные 9 кодовых слов сообщения размещают в первичном сообщении в знаках символа со 2-го по 10-й, а остаток - во вторичном сообщении, начиная со знака символа 21. Если кодовые слова сообщения не полностью заполняют все области в символе, отведенные под сообщение, добавляют кодовые слова, представляющие знак Pad (ЗАПОЛНИТЕЛЬ). Структура символа MaxiCode такова, что управляющие знаки символики и последующие знаки сообщения, на которые они действуют, могут появляться в различных сообщениях и подмножествах коррекции ошибок, но это не влияет на кодирование сообщения.
После того, как кодовые слова данных разделены на сообщения, а затем на подмножества коррекции ошибок, исправление ошибок будет применяться, как определено в 4.10. В результате и данные, и кодовые слова коррекции ошибок включают в графический символ в соответствии с рисунками 4 и 5.
В приложении Н приведен пример кодирования MaxiCode (поясняющий указанные этапы).
4.8. Режимы
MaxiCode предоставляет режимы, которые используют для определения структурирования данных и коррекции ошибки внутри символа. Режим кодируется как часть первичного сообщения (4.7.1)
4.8.1 Режим 0: Устаревший
Режим 0 является устаревшим. Он заменен режимами 2 и 3. Режим 0 установлен в [4].
4.8.2 Режим 1: Устаревший
Режим 1 является устаревшим. Он заменен режимом 4.
4.8.3 Режимы 2 и 3: Структурированное сообщение носителя
Режимы 2 и 3 разработаны для использования в транспортной отрасли. Они кодируют адрес пункта назначения (adress destination) и класс обслуживания (class of service), как определено носителем. Структура сообщения определяется в приложении В. Первые 120 битов используют для кодирования структурированного сообщения носителя при помощи расширенной коррекции ошибок (EEC). Остальные символы могут использоваться для других целей и применяют стандартную коррекцию ошибок (SEC).
4.8.4 Режим 4: Стандартный символ
В режиме 4 символ использует расширенную коррекцию ошибок (EEC) в первичном сообщении и стандартную коррекцию ошибок (SEC) во вторичном сообщении. Режим 4 содержит 93 кодовых слова для кодирования данных.
4.8.5 Режим 5: Полная расширенная коррекция ошибок (EEC)
В режиме 5 символ использует расширенную коррекцию ошибок (EEC) как в первичном, так и во вторичном сообщении. Этот режим содержит 77 кодовых слов для кодирования данных.
4.8.6 Режим 6: Программирование устройства считывания
В режиме 6 символ кодирует сообщение, используемое для программирования считывающей системы. Во вторичном сообщении используют стандартную коррекцию ошибок (SEC). При считывании символа в режиме 6 данные не передаются.
4.8.7 Индикаторы режима
Режим следует кодировать первым знаком символа с использованием модулей с 3-го по 6-й, как определено в таблице 4.
Таблица 4 - Режимы MaxiCode
|
Режим |
Описание |
Числа модуля 3456 |
|
0 |
Устаревший |
0000 |
|
1 |
Устаревший |
0001 |
|
2 |
Структурированное сообщение носителя - цифровой почтовый код |
0010 |
|
3 |
Структурированное сообщение носителя - алфавитно-цифровой почтовый код |
0011 |
|
4 |
Стандартный символ со стандартной коррекцией ошибок (SEC) |
0100 |
|
5 |
Символ с расширенной коррекцией ошибок (EEC) |
0101 |
|
6 |
Программируемые устройства считывания, стандартная коррекция ошибок (SEC) |
0110 |
|
Примечание - Все режимы и комбинации битов, не определенные в данной таблице, зарезервированы для будущего использования. | ||
4.9 Структурированное соединение
4.9.1 Основные принципы
В структурированный формат может быть объединено до восьми символов MaxiCode.
Если символ является частью структурированного соединения, то это должно быть отражено последовательностью двух знаков символа в установленных позициях символа в зависимости от режима.
Последовательность индикатора структурированного соединения состоит из двух знаков символа:
a) знака Pad (ЗАПОЛНИТЕЛЬ) (знака символа со значением 33), который должен быть первым знаком символа,
b) знака символа, который указывает позицию символа в комплекте символов MaxiCode в формате структурированного соединения, т.е. в формате m из n символов.
Первые три бита второго кодового слова идентифицируют позицию конкретного символа с двоичным значением (m-1). Последние три бита идентифицируют общее число символов с двоичным значением (n-1), вставляемых в формат структурированного соединения. 3-битовые комбинации должны быть согласованы с комбинациями, определенными в таблице 5.
Таблица 5 - Позиция символа структурированного соединения
|
Позиция символа |
Биты |
Общее число символов |
Биты 456 |
|
1 |
000 |
|
|
|
2 |
001 |
2 |
001 |
|
3 |
010 |
3 |
010 |
|
4 |
011 |
4 |
011 |
|
5 |
100 |
5 |
100 |
|
6 |
101 |
6 |
101 |
|
7 |
110 |
7 |
110 |
|
8 |
111 |
8 |
111 |
Пример:
Определение третьего символа из набора семи символов кодируется следующим образом:
Третья позиция: 010
Все 7 символов: 110
Комбинация битов: 010110
Кодовое слово: 22
4.9.2 Структурированное соединение и режимы 2 и 3
Для режимов 2 и 3 последовательность индикатора структурированного соединения должна быть размещена в первых двух знаках символа вторичного сообщения, т.е. ![]() и
и ![]() . Знак символа
. Знак символа ![]() начинает нормальное кодирование данных в кодируемом наборе А. При использовании в структурированном соединении режима 2 или 3 все эти символы должны быть в одном режиме, а первичное сообщение должно повторяться в каждом символе.
начинает нормальное кодирование данных в кодируемом наборе А. При использовании в структурированном соединении режима 2 или 3 все эти символы должны быть в одном режиме, а первичное сообщение должно повторяться в каждом символе.
4.9.3 Структурированное соединение в режимах с 4-го по 6-й
Для режимов с 4-го по 6-й последовательность индикатора структурированного соединения должна быть размещена в первом и втором знаке символа первичного сообщения, т.е. в знаках символа ![]() и
и ![]() . Знак символа
. Знак символа ![]() начинает нормальное кодирование данных в кодируемом наборе А.
начинает нормальное кодирование данных в кодируемом наборе А.
4.9.4 Операции с использованием и без использования буфера
Сообщение в составе последовательности структурированного соединения в устройстве считывания может полностью использовать буфер, т.е. передаваться после того, как считаны все символы. Кроме того, устройство считывания может передавать декодированные данные в каждом символе по мере считывания. В этой операции без использования буфера протокол ECI для структурированного соединения определяет управляющий блок, который будет предварять начало каждой передачи.
4.10 Обнаружение и исправление ошибок
Символы MaxiCode используют исправление ошибок Рида-Соломона на одном из двух уровней:
стандартная коррекция ошибок (SEC);
расширенная коррекция ошибок (EEC).
Деление символов MaxiCode на первичное и вторичное сообщения и подразделение вторичного сообщения на два чередующихся подмножества позволяет применять исправление ошибок. Исправление ошибок применяют независимо для каждой из трех частей деления.
Для заданной последовательности кодовых слов данных (т.е. первичного сообщения или подмножества вторичного сообщения) кодовые слова коррекции ошибок должны быть вычислены с использованием алгоритма кода с исправлением ошибок Рида-Соломона.
Полиномиальная арифметика для MaxiCode выполняет вычисления с использованием арифметики по битам по модулю 2 и арифметику по словам по модулю 1000011 (десятичное 67). Эта арифметика основана на поле Галуа 2![]() с 1000011 представлением полинома простого модуля этого поля:
с 1000011 представлением полинома простого модуля этого поля: ![]() .
.
4.10.1 Расширенная коррекция ошибок (EEC) в первичном сообщении
Расширенная коррекция ошибок (EEC) должна использоваться в первичном сообщении. Она требует 10 кодовых слов коррекции ошибок.
Порождающий полином ![]() для расширенной коррекции ошибок (EEC) в первичном сообщении:
для расширенной коррекции ошибок (EEC) в первичном сообщении:
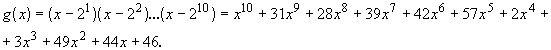
4.10.2 Исправление ошибок во вторичном сообщении
Во вторичном сообщении используют один из следующих уровней коррекции ошибок:
- расширенная коррекция ошибок (EEC), требующая 28 кодовых слов коррекции ошибок на подмножество;
- стандартная коррекция ошибок (SEC), требующая 20 кодовых слов коррекции ошибок на подмножество.
Порождающий полином ![]() для расширенной коррекции ошибок (EEC) во вторичном сообщении:
для расширенной коррекции ошибок (EEC) во вторичном сообщении:
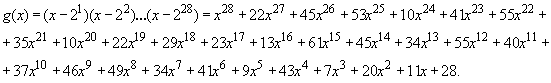
Порождающий полином ![]() для стандартной коррекции ошибок (SEC) во вторичном сообщении:
для стандартной коррекции ошибок (SEC) во вторичном сообщении:
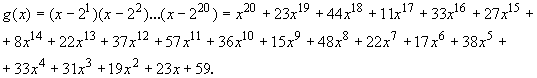
4.10.3 Генерация кодовых слов коррекции ошибок
Кодовые слова коррекции ошибок являются остатком от деления ![]() кодовых слов данных на порождающий полином
кодовых слов данных на порождающий полином ![]() k-й степени. В MaxiCode это осуществляется отдельно для каждой части деления коррекции ошибок.
k-й степени. В MaxiCode это осуществляется отдельно для каждой части деления коррекции ошибок.
Кодовые слова данных являются коэффициентами для членов полинома, причем коэффициент при члене старшего порядка является первым кодовым словом, а коэффициент при члене младшего порядка - последним кодовым словом, стоящим перед первым кодовым словом коррекции ошибок. Коэффициент при члене старшей степени остатка от деления является первым кодовым словом коррекции ошибок, коэффициент при члене нулевой степени остатка от деления - последним кодовым словом коррекции ошибок из регистра.
Кодовые слова коррекции ошибок могут быть генерированы с использованием схемы деления (рисунок 7). Регистры с ![]() по
по ![]() обнуляют. Существуют две фазы генерации кодирования. В первой фазе с переключением в нижнее положение данные символа передаются как на выход, так и в схему. Первая фаза заканчивается после
обнуляют. Существуют две фазы генерации кодирования. В первой фазе с переключением в нижнее положение данные символа передаются как на выход, так и в схему. Первая фаза заканчивается после ![]() тактовых импульсов. Во второй фазе (
тактовых импульсов. Во второй фазе (![]() ...
... ![]() тактовых импульсов) с переключением в верхнее положение кодовые слова коррекции ошибок генерируются поочередным сбрасыванием регистров, в то время как входные данные сохраняются нулевыми. Кодовые слова, выходящие из регистра переключения, находятся в том порядке, в каком они будут размещаться в символе. Из-за того, что вторичное сообщение является чередующимся, кодовые слова не будут размещаться в последовательных знаках символа.
тактовых импульсов) с переключением в верхнее положение кодовые слова коррекции ошибок генерируются поочередным сбрасыванием регистров, в то время как входные данные сохраняются нулевыми. Кодовые слова, выходящие из регистра переключения, находятся в том порядке, в каком они будут размещаться в символе. Из-за того, что вторичное сообщение является чередующимся, кодовые слова не будут размещаться в последовательных знаках символа.
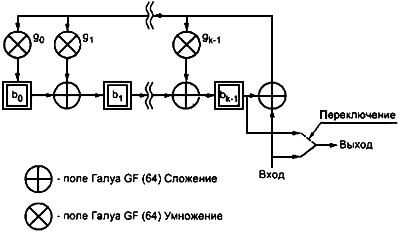
Рисунок 7 - Схема кодирования кодовых слов коррекции ошибок
4.10.4 Возможности исправления ошибок
Кодовые слова коррекции ошибок могут исправить два типа ошибочных кодовых слов, стирания (ошибочные кодовые слова с известным местонахождением) и ошибки подстановки знака (ошибочные кодовые слова с неизвестным местонахождением). Стирание - это несканируемый или недекодируемый знак символа, ошибка подстановки знака - неправильно декодированный знак символа. Число исправляемых ошибок подстановки знака и стираний определяют по формуле
![]() ,
,
где ![]() - число стираний;
- число стираний;
![]() - число ошибок подстановки знака;
- число ошибок подстановки знака;
![]() - число кодовых слов коррекции ошибок.
- число кодовых слов коррекции ошибок.
Если большая часть возможности коррекции ошибок израсходована на исправление стираний, возрастает возможность появления неустановленных ошибок подстановки знака. Если число ошибок подстановки знака менее десяти, а число стираний более половины числа кодовых слов коррекции ошибок, то формула выглядит следующим образом:
![]() .
.
Следует заметить, что равенство означает, что при большом количестве стираний может возникнуть необходимость зарезервировать четыре знака коррекции ошибок. В противном случае существует риск того, что символ будет неправильно декодирован.
4.11 Размеры
4.11.1 Размеры символа
![]() - длина символа, измеряемая от центра крайнего левого модуля до центра крайнего правого модуля в верхней строке символа.
- длина символа, измеряемая от центра крайнего левого модуля до центра крайнего правого модуля в верхней строке символа. ![]() может изменяться от 24,00 до 27,00 мм.
может изменяться от 24,00 до 27,00 мм.
![]() - высота символа, измеряемая от центра верхней строки до центра нижней строки. Номинальное значение
- высота символа, измеряемая от центра верхней строки до центра нижней строки. Номинальное значение ![]() относительно
относительно ![]() :
: ![]() .
.
4.11.2 Размеры шестиугольного модуля
Шестиугольные модули в символе MaxiCode расположены в строках со смещением, каждая из которых включает от 29 до 30 модулей. Четыре измерения определяют размеры и расположение модулей по отношению друг к другу (рисунок 8).
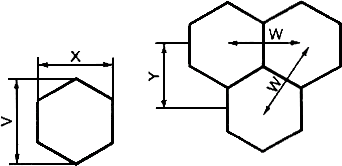
![]() - высота модуля по вертикали;
- высота модуля по вертикали;
![]() - расстояние между центрами соседних модулей;
- расстояние между центрами соседних модулей;
![]() - ширина модуля по горизонтали;
- ширина модуля по горизонтали;
![]() - расстояние по вертикали от центральной линии модуля одной строки до центральной линии модуля соседней строки
- расстояние по вертикали от центральной линии модуля одной строки до центральной линии модуля соседней строки
Рисунок 8 - Размеры модуля MaxiCode
Во избежание проблем, связанных с накоплением допусков в символе, размеры модулей должны базироваться на длине символа ![]() . Должна быть выбрана достижимая длина
. Должна быть выбрана достижимая длина ![]() в соответствии с технологией печати и списком значений, указанных в 4.11.3 (приложение J). Базируясь на величине
в соответствии с технологией печати и списком значений, указанных в 4.11.3 (приложение J). Базируясь на величине ![]() , вычисляют номинальные размеры
, вычисляют номинальные размеры ![]() ,
, ![]() ,
, ![]() и
и ![]() . Соотношения и размеры модуля приведены в таблице 6.
. Соотношения и размеры модуля приведены в таблице 6.
Таблица 6 - Размер темного модуля
|
Номинальный размер |
Допуск, мм |
|
Ширина ( |
±0,12 |
|
Высота ( |
±0,12 |
4.11.3 Размеры и допуски темного шестиугольника
В таблице 7 приведены размеры для шестиугольного модуля в сетке, указанной на рисунке 5. Для лучшего декодирования темные шестиугольники не должны примыкать друг к другу. Действительные размеры темных шестиугольников указаны в таблице 7.
Таблица 7 - Размеры модуля MaxiCode относительно ![]()
|
Размер |
Относительно других размеров |
Размер относительно |
|
|
|
0,88 |
|
|
|
1,02 |
|
|
|
0,88 |
|
|
|
0,76 |
|
Н |
H=32 |
24,37 |
В приложении J приведены практические рекомендации по печати, включающие разработку шрифтов для темных шестиугольников.
4.11.4 Размеры шаблона поиска
Шаблон поиска должен соответствовать определенному в 4.2.1.1 и приведенному на рисунке 3. Размеры шаблона поиска должны соответствовать нижеуказанным и приведены на рисунке 9.
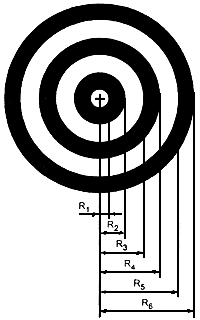
Рисунок 9 - Размеры шаблона поиска MaxiCode
Шаблон поиска должен быть концентрическим с центром в модуле, расположенном на расстоянии 16![]() выше центра модулей нижней строки символа и на расстоянии 14
выше центра модулей нижней строки символа и на расстоянии 14![]() правее центра крайнего левого модуля строки.
правее центра крайнего левого модуля строки.
Ширина светлых и темных колец обычно одинакова. Шаблон поиска определяют по радиусам переходов от светлого к темному и от темного к светлому, от ![]() до
до ![]() , где
, где ![]() основан на гладкой кривой, усредняющей неравность пикселей. Размеры указанных радиусов приведены в таблице 8.
основан на гладкой кривой, усредняющей неравность пикселей. Размеры указанных радиусов приведены в таблице 8.
Таблица 8 - Размеры шаблона поиска
|
Обозначение размера |
Номинальный размер, мм |
|
|
0,51 |
|
|
1,18 |
|
|
1,86 |
|
|
2,53 |
|
|
3,20 |
|
|
3,87 |
Внутренняя свободная зона, окружающая шаблон поиска, определяется расположением модулей. Эта зона должна быть свободной от любых непредусмотренных пометок.
В приложении J содержатся практические рекомендации по печати.
4.11.5 Свободные зоны
Для символов MaxiCode необходимы следующие свободные зоны, измеряемые от внешних краев:
1![]() с левой и с правой стороны,
с левой и с правой стороны,
1![]() сверху и снизу.
сверху и снизу.
Размеры свободных зон должны быть выдержаны между символом MaxiCode и любыми смежными напечатанными изображениями.
4.11.6 Общий размер символа
Общие размеры символа MaxiCode, включая свободные зоны, составляют 32![]() по длине и (34
по длине и (34![]() +
+![]() ) по высоте. Размеры любого символа MaxiCode должны быть от 26,48 мм по ширине и 25,32 мм по высоте до 29,79 мм по ширине и 28,49 мм по высоте.
) по высоте. Размеры любого символа MaxiCode должны быть от 26,48 мм по ширине и 25,32 мм по высоте до 29,79 мм по ширине и 28,49 мм по высоте.
4.11.7 Практические рекомендации по печати
Системы печати могут быть неспособными достигать указанных номинальных размеров. В приложении J приведены практические рекомендации по печати.
4.12 Руководство для пользователя
4.12.1 Визуальное представление знаков
В связи с тем, что символы MaxiCode способны кодировать значительное число знаков, визуальное представление знаков данных может оказаться непрактичным. Предпочтительнее, чтобы символ сопровождался описательным, а не закодированным текстом. Размеры знаков и тип шрифта не регламентированы, и сообщение может быть напечатано в любом месте в области, окружающей символ. Визуальное представление знаков не должно перекрывать символ и свободные зоны.
4.12.2 Приспособленность к автоматическому распознаванию
MaxiCode может использоваться в системах автоматического распознавания вместе с рядом других символик (приложение К).
4.13 Качество символа
Качество символов MaxiCode должно быть оценено использованием руководства по качеству печати символа двумерного матричного штрихового кода (приложение С), а также нижеуказанных положений.
4.13.1 Получение изображения для испытаний
Черно-белое изображение символа для испытаний должно быть получено с разрешением не менее 16 точек/мм (400 точек/дюйм). Для получения изображения рекомендуется использовать стационарный планшетный страничный сканер, установленный в режим плоского линейного 8-битового черно-белого сканирования. В качестве альтернативы можно также использовать устройство на основе точной видеокамеры (C.1), однако страничные сканеры с подачей и ручные сканеры не обеспечивают пространственной точности, необходимой для испытаний качества символа.
4.13.2 Параметры качества символа
4.13.2.1 Декодирование
Рекомендуемый алгоритм декодирования, приведенный в 4.14, применяют к изображению для испытаний. Если в результате получится правильно декодированное полное сообщение данных, то декодирование считают успешным (класс А или 4,0), в противном случае оно считается неудовлетворительным (класс F или 0,0).
4.13.2.2 Контраст символа
Как часть рекомендуемого декодирования, из изображения для испытаний получается черно-белое изображение с разрешением 4 точки/мм (100 точек/дюйм). Коэффициенты отражения от темного и светлого и контраст символа определяют в соответствии с С.2.2.
4 13.2.3 Изменения "печати"
Изменения "печати" должны быть оценены проверкой отношения площади, заполненной изолированными темными модулями, к площади идеального шестиугольного модуля в символе. Подсчитывают смежные темные или светлые биты в изображении с разрешением 16 точек/мм (400 точек/дюйм), которое переведено в двоичную систему, используя порог, определенный на этапе 3 рекомендуемого алгоритма декодирования.
Если переведенное в двоичную систему изображение имеет пиксельное разрешение R точек/мм, а рекомендуемое декодирование дает среднее расстояние между центрами модулей ![]() , то площадь, отведенная для каждого шестиугольного модуля в сетке, будет
, то площадь, отведенная для каждого шестиугольного модуля в сетке, будет ![]() пикселей.
пикселей.
Из рекомендуемого декодирования темные шестиугольные модули, окруженные со всех шести сторон светлыми модулями, могут быть определены и размещены в изображении. Должно быть подсчитано количество смежных темных пикселей поблизости от каждого такого изолированного модуля, затем подсчитывают их среднее значение для получения средней площади темного модуля ![]() . При нормировании
. При нормировании ![]() к отведенной площади
к отведенной площади ![]() , получим относительную площадь измеренных темных модулей
, получим относительную площадь измеренных темных модулей ![]() .
.
Оптимальный размер темного шестиугольника составляет 75% отведенной площади и может быть достигнут подрезанием печатного шаблона (приложение J). Когда размер темных шестиугольников отклоняется от оптимального, способность к считыванию снижается. Таким образом, при номинальной печати MaxiCode должны получаться изолированные темные модули с ![]() =0,75, при этом максимально допустимая область
=0,75, при этом максимально допустимая область ![]() =0,95, а минимальная
=0,95, а минимальная ![]() =0,55.
=0,55.
Определяют:
![]()
![]()
![]()
![]()
Для определения класса изменения "печати" применяют метод, указанный в С.2.3.
4.13.2.4 Осевая и локальная неоднородность
На этапе 11 рекомендуемого алгоритма декодирования путем обратного быстрого преобразования Фурье создается изображение центров модулей. Точное расположение этих выборочных точек относительно соседних составляет основу оценки осевой и локальной неоднородности.
Фиксированное масштабирование символов MaxiCode вместе с методом получения масштабной сетки изменяет и расширяет полезные оценки качества символа относительно осевой неоднородности. Для MaxiCode определяют "глобальную" неоднородность, которая заключается в том, что MaxiCode обеспечивает масштабирование символа вдоль каждой из трех многоугольных осей в абсолютных пределах. В дополнение определяют "локальную" осевую неоднородность, которая защищает от искажения сетки вдоль любой оси, которые могут повредить считываемости символа.
Вдоль каждой из трех основных осей MaxiCode измеряют расстояние между каждой парой смежных выборочных точек. В соответствии с нижеуказанным определяют среднее расстояние ![]() , максимальное расстояние
, максимальное расстояние ![]() и минимальное
и минимальное ![]() , которые используют для оценки двух независимых параметров качества.
, которые используют для оценки двух независимых параметров качества.
4.13.2.4.1 Осевая неоднородность
MaxiCode - это символика фиксированного размера с номинальным расстоянием между центрами модулей данных, равным 0,88 мм. Таким образом, общий размер символа остается в пределах, указанных в 4.11.1. Каждое из трех среднесеточных расстояний должно оцениваться по следующим классам:
класс А (4,0) - при 0,820 мм![]() 0,940 мм;
0,940 мм;
класс F (0,0) - при ![]() <0,820 мм или
<0,820 мм или ![]() >0,940 мм.
>0,940 мм.
Класс осевой неоднородности символа есть наименьшее значение из полученных для любой из его трех осей.
4.13.2.4.2 Локальная неоднородность
Степень отличия максимального и минимального расстояний между выборочными точками модуля вдоль каждой оси от их среднего показывает уровень варьирования или разрывов в шестиугольной сетке символа. Независимо для каждой оси локальную неоднородность оценивают следующим образом:
класс А (4,0) - при ![]() ;
;
класс В (3,0) - при ![]() ;
;
класс С (2,0) - при ![]() ;
;
класс D (1,0) - при ![]() ;
;
класс F (0,0) - при ![]() .
.
Класс осевой неоднородности символа есть наименьшее из значений, полученных для любой из его трех осей.
4.13.2.5 Неиспользуемая коррекция ошибок
Для исправления ошибок символ MaxiCode разделяют на подмножество первичного сообщения и два чередующихся подмножества вторичного сообщения. Каждое из этих трех подмножеств Рида-Соломона должно оцениваться независимо в соответствии с С.2.5, тогда класс неиспользуемой коррекции ошибок (Unused Error Correction - UEC) должен соответствовать наименьшему из значений, полученных для любого подмножества.
4.13.3 Полный класс символа
Полный класс качества печати символа MaxiCode соответствует наименьшему из шести вышеуказанных классов. В таблице 9 приведены все классы критериев испытания качества печати.
Таблица 9 - Перечень параметров качества печати символа MaxiСоde
|
Класс |
Рекомен- дуемое декоди- рование |
Контраст символа |
|
|
Локальная неоднородность |
Неиспользуемая коррекция ошибок (UEC) |
|
А (4,0) |
Успешно |
SC |
|
|
|
UEC |
|
В (3,0) |
|
SC |
|
|
|
UEC |
|
С (2,0) |
|
SC |
|
|
|
UEC |
|
D (1,0) |
|
SC |
|
|
|
UEC |
|
F (0,0) |
Отсутствует |
SC |
|
Иное (т.е при |
|
UEC |
4.13.4 Измерения для управления процессом
Существуют различные инструменты и методы, позволяющие производить практические измерения для контроля и управления процессом создания символов MaxiCode. Они включают:
1) считывание контраста символа с помощью верификатора линейного штрихового кода;
2) шаблонный отпечаток для визуальной проверки "приращения" шаблона поиска, шаблонов ориентации и размера всего символа;
3) напечатанный специальный шаблон для визуального обнаружения локальной неоднородности сетки;
4) визуальную проверку "приращения" темного модуля и дефектов.
Методы управления процессом приведены в приложении ![]() .
.
4.14 Рекомендуемый алгоритм декодирования
Рекомендуемый алгоритм декодирования позволяет обнаружить символы в изображении и декодировать их. Указанный алгоритм декодирования используют для определения качества символа:
1) определяют местонахождение потенциальных шаблонов поиска с использованием огрубленного алгоритма обнаружения следующим образом.
Одномерный образец, представляющий линейный сигнал, проходящий через центр шаблона поиска, строится как образец ограниченной длины с прямоугольными колебаниями, изображенный на рисунке 10, где штрихпунктирная линия показывает центр шаблона поиска.
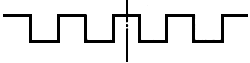
Рисунок 10 - Образец с прямоугольными колебаниями
Шаблон поиска, определяемый в MaxiCode, рассматривают как композицию трех черных и трех белых чередующихся колец. Составной образец, проходящий через центр шаблона поиска, начинают с точки высокой интенсивности, представляющей одну сторону наибольшего белого кольца, окруженного наибольшим черным кольцом, и заканчивают точкой высокой интенсивности, представляющей другую сторону того же белого кольца. Из полученного изображения MaxiCode извлекают линейный сигнал, начинающийся с первой строки изображения, и сравнивают с образцом путем подсчета коэффициента взаимной корреляции. Измерением интенсивности сигнала определяют участок низкой интенсивности шириной, совпадающей с ожидаемым размером шаблона поиска, т.е. 3 пикселя. Если за участком с низкой интенсивностью следует участок с высокой интенсивностью, это может служить сигналом о начале шаблона поиска. Поэтому процесс сопоставления не начинают до тех пор, пока не обнаружен такой участок с низкой интенсивностью. Коэффициент корреляции для каждого сопоставления регистрируют в виде строки по мере продвижения образца, определяют максимальный коэффициент и сравнивают с порогом в 70%. Каждый линейный сигнал изображения последовательно проверяют на ближайшее совпадение.
Если такое совпадение произошло, извлекают линейный сигнал вдоль столбца изображения в центре совпадающего сигнала для сопоставления с подобным образцом. Если коэффициент корреляции в соответствующем столбце не находит подходящего соответствия, то процедуру повторяют вдоль строк. Одновременное совпадение по строке и столбцу означает обнаружение шаблона поиска в данном изображении. Если при достижении последней строки шаблон поиска не обнаружен, это означает, что в данном изображении шаблон поиска отсутствует;
2) заново масштабируют изображение до фиксированного горизонтального и вертикального разрешения 4 точки/мм;
3) собирают значения коэффициентов отражения со всех пикселей в квадрате, непосредственно охватывающем область нахождения предполагаемого шаблона поиска, и определяют порог "черное-белое" с использованием методов, приведенных в К.2.2 и К.2.3;
4) основываясь на пороге, разбивают значения модулей на два множества по шкале от минус 127 до плюс 128 с порогом светлое-темное, установленным в нуль;
5) проверяют, является ли действительным идентифицированный предполагаемый шаблон поиска, следующим образом:
a) генерируют точное корреляционное ядро подстановкой значений из таблицы 8 и значения разрешения (RES), равного 4 точки/мм, в формулу (1)
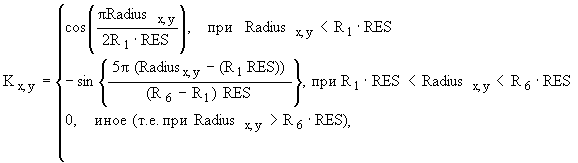 (1)
(1)
где RES - разрешение изображения в точках/мм;
размер ядра =![]() =
=![]() ;
;
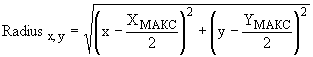 .
.
Это приводит к формуле (2),
 (2)
(2)
где размер ядра =![]() =
=![]() =31
=31
;
b) копируют шаблон поиска в буфер (![]() ), который имеет тот же размер, что и ядро. Размещают центр шаблона поиска в точку (
), который имеет тот же размер, что и ядро. Размещают центр шаблона поиска в точку (![]() ,
,![]() );
);
c) вычисляют процент корреляции ![]() по формуле (3)
по формуле (3)
 , (3)
, (3)
где ![]() - изображение данных потенциального шаблона поиска;
- изображение данных потенциального шаблона поиска;
Contrast - контраст изображения данных (т.е. МАХ[![]() ] - MIN [
] - MIN [![]() ]),
]),
![]() - процент корреляции;
- процент корреляции;
d) если ![]() >85%, то корреляция соответствует требованиям;
>85%, то корреляция соответствует требованиям;
6) очищают шаблон поиска с нулевыми значениями пикселей;
7) создают второе изображение, в котором содержатся только расположения краев между светлым и темным. Эти края должны быть установлены в нуль, а прочие области должны превышать нуль;
8) при использовании стационарных устройств считывания, очищают область вне круга, наложенного на увеличенное изображение с размером пикселя, вычисленным как среднее арифметическое белых шестиугольных выборок внутри круга. Диаметр круга составляет 95% размера символа (его высоты);
9) преобразуют пространственный домен изображения в периодический с помощью двумерного быстрого преобразования Фурье. Самой яркой точкой в преобразованной плоскости будет точка (0,0), соответствующая компоненте DC (центр домена) изображения. Шесть точек, окружающих центральную точку, представляют шаг, направление и плотность краев между шестиугольниками;
10) обнаруживают и отсеивают яркие точки исключением любых точек периодического домена, которые не соответствуют требуемому шагу и направлению границ шестиугольников. Поскольку изображение реально оценено, периодический домен симметричен относительно начала координат. Поэтому только три яркие точки в половине плоскости преобразования действительно идентифицированы.
Примечание - Поскольку это осуществляется в периодическом домене, на практике не проводят анализ пространственного распределения модулей. Яркие пятна периодического домена соответствуют гармоникам расположения краев;
11) проводят двумерное обратное быстрое преобразование Фурье для возврата к пространственному домену, восстанавливая таким образом изображение центров шестиугольников.
Примечание - В новом изображении центры шестиугольников имеют большую величину. Действительная величина белых центров в центрах шестиугольников зависит от количества краев, находящихся в их окружении;
12) определяют ориентацию символа. Шестиугольники MaxiCode имеют три оси, отстоящие на 60° друг от друга. Направление этих трех осей устанавливается по самым ярким точкам периодической области. Основываясь на информации о ярких точках, можно вычислить расположение шаблонов ориентации. Информация в шаблонах ориентации определяет ориентацию изображения;
13) преобразуют информацию в шестиугольниках в битовую информацию и выстраивают биты в виде временного последовательного потока битов;
14) разделяют поток битов на первичное и вторичное сообщения, создавая потоки битов от 1 до 120 и от 121 до 864;
15) применяют коррекцию ошибок к потоку битов для первичного сообщения:
a) вычисляют синдромы;
b) вычисляют полином обнаружения ошибок по алгоритму Берлекэмпа-Мейси (Berlekamp-Massey);
c) вычисляют обнаружение ошибок с помощью поиска Чьена (Chien);
d) вычисляют правильное значение каждого ошибочного кодового слова по алгоритму Форни (Forny);
e) если на этапах 15с) и 15d) обнаружено исправляемое количество ошибок, то декодируют данные из кодовых слов. В противном случае используют метод, приведенный в приложении D.
16) идентифицируют уровень коррекции ошибки, используемый во вторичном сообщении на основе битов режима;
17) применяют коррекцию ошибки к потоку битов для каждого сегмента вторичного сообщения, используя последовательность, установленную на этапе 15.
4.15 Передаваемые данные
Передача данных для соответствующих устройств считывания устанавливается стандартным протоколом. Указанные устройства считывания можно запрограммировать для поддержки иных видов передачи.
4.15.1 Основная интерпретация
Кодируемые данные не должны передаваться из символов режима 6. В противном случае все кодовые слова должны быть преобразованы в поток данных следующим образом:
a) все кодовые слова коррекции ошибки должны быть отброшены;
b) все управляющие знаки символики Shift (РЕГИСТР) и Latch (ФИКСАТОР) должны выполнять свои функции для переключения к другим кодируемым наборам. Знак [NS] ([ЦР]) должен преобразовывать последующие пять кодовых слов (эквивалентных 30 двоичным битам) в 9 цифр;
c) кодовое слово [ECI] вызывает преобразование следующих от одного до четырех кодовых слов в шестиразрядное число, предваряемые знаком "\" (ОБРАТНАЯ ДРОБНАЯ ЧЕРТА) (4.15.2);
d) все данные должны переводиться в данные пользователя как 8-битные байты;
e) при режимах 4 и 5 данные передают в той же последовательности, в какой они закодированы в символе. При режимах 2 и 3 последовательность передачи данных приведена в приложении В.
4.15.2 Протокол интерпретации расширенного канала (ECI)
В системах, поддерживающих интерпретации расширенного канала (ECI), необходимо использовать префикс идентификатора символики при каждой передаче. Кодовое слово [ECI] всегда должно передаваться как управляющий знак с десятичным значением 92 (или значение 5![]() ), который представляет знак "\", или ОБРАТНАЯ ДРОБНАЯ ЧЕРТА в кодировке по умолчанию. Следующее кодовое слово (слова) преобразуется в шестиразрядное число путем применения в обратной последовательности правил, описанных в таблице 3. Шестиразрядное число передается как знаки версии КОИ-7 с соответствующими десятичными значениями (48-57).
), который представляет знак "\", или ОБРАТНАЯ ДРОБНАЯ ЧЕРТА в кодировке по умолчанию. Следующее кодовое слово (слова) преобразуется в шестиразрядное число путем применения в обратной последовательности правил, описанных в таблице 3. Шестиразрядное число передается как знаки версии КОИ-7 с соответствующими десятичными значениями (48-57).
Программное обеспечение в применении, распознав \nnnnnn, должно интерпретировать все последующие знаки как знаки из интерпретации расширенного канала (ECI), определяемые данной шестиразрядной последовательностью. Эта интерпретация действует до конца кодируемых данных или до обнаружения другой последовательности ECI.
Если знак "\" (байт с десятичным значением 92) требуется использовать в качестве кодируемых данных, передача должна осуществляться следующим образом: всегда, когда знак версии КОИ-7 с десятичным значением 92 встречается как данные, должны быть переданы два байта с таким значением. Таким образом, если встречается один знак, то это всегда управляющий знак, а два знака означают непосредственно данные.
Пример:
|
Кодируемые данные: |
А\\В\С | |
|
Передача: |
А\\\\В\\С |
Использование идентификатора символики гарантирует правильность интерпретации применением управляющего знака.
4.15.3 Идентификатор символики
ГОСТ Р 51293.1 обеспечивает стандартную процедуру сообщения считанной символики вместе с опциями, устанавливаемыми в декодере, и любыми специальными параметрами, закодированными в символе.
После идентификации структуры данных (включая возможное использование любой ИРК (ECI)) к передаваемым данным в качестве преамбулы должен быть добавлен декодером соответствующий идентификатор символики; при использовании ECI требуется идентификатор символики. В приложении Е описаны идентификатор символики и дополнительные значения, применимые к MaxiCode.
4.15.4 Пример передаваемых данных
В настоящем примере двузначное сообщение "¶Ж" кодируется в MaxiCode в режиме 4. Знак "¶"представлен байтом версии КОИ-8 с целочисленным значением 182 в кодируемом наборе MaxiCode по умолчанию (ECI 000003, что эквивалентно ИСО 8859-1). "Ж" - это знак кирилловского алфавита, которого нет в ECI 000003, но который может быть представлен в ИСО 8859-5* (ECI 000007) тем же целочисленным значением 182. Поэтому полное сообщение может быть представлено с помощью вставки переключения к ECI 000007 после первого знака, как показано ниже.
_____________
* В приложении N приведены сведения о наборе знаков ИСО 8859-5.
Символ кодирует сообщение <¶><Переключение к ECI 000007><Ж>, используя следующую последовательность кодовых слов MaxiCode (отметим, что переключение к кодируемому набору Е, за которым следует кодовое слово со значением 47, кодирует целочисленное значение байта 182:
[Shift E][47][ECI][7][Shift E][47],
с десятичными значениями
[62],[47],[27],[7],[62],[47].
Декодер передает следующие байты (включая префикс идентификатора символики и дополнительное значение 2, означающее использование протокола ЕСI):
93, 85, 50, 182, 92, 48, 48, 48, 48, 48, 55, 182,
которые при полном просмотре в интерпретации по умолчанию графически отобразятся следующим образом:
]U2H¶\000007¶
Следует отметить, что декодер отвечает за сигнализацию переключения к ЕСI 000007, но не за интерпретацию результата.
Программное обеспечение в применении получателя, распознающее ЕСI, удалит переключающую последовательность ЕСI \000007, и знак Ж будет представлен в зависимости от системы (т.е. изменением шрифта в специальном файле). Конечный результат совпадет с первоначальным сообщением "¶Ж".
ПРИЛОЖЕНИЕ А
(обязательное)
Основное кодирование знаков MaxiCode: набор знаков по умолчанию
|
Значение знака символа |
Расположение знаков в кодируемых наборах | |||||||||||||||
|
|
Кодируемый набор А |
Кодируемый набор В |
Кодируемый набор С |
Кодируемый набор D |
Кодируемый набор Е | |||||||||||
|
Деся- |
Двоич- |
Знак |
Значение КОИ-8 |
Знак |
Значение КОИ-8 |
Знак |
Значение КОИ-8 |
Знак |
Значение КОИ-8 |
Знак |
Значение КОИ-8 | |||||
|
0 |
000000 |
CR(BK) |
13 |
` |
96 |
|
192 |
|
224 |
NUL(ПУC) |
0 | |||||
|
1 |
000001 |
А |
65 |
а |
97 |
|
193 |
|
225 |
SOH(HЗ) |
1 | |||||
|
2 |
000010 |
В |
66 |
b |
98 |
|
194 |
|
226 |
STX(HT) |
2 | |||||
|
3 |
000011 |
С |
67 |
с |
99 |
|
195 |
|
227 |
ETX(KT) |
3 | |||||
|
4 |
000100 |
D |
68 |
d |
100 |
|
196 |
|
228 |
ЕОТ(КП) |
4 | |||||
|
5 |
000101 |
Е |
69 |
е |
101 |
|
197 |
|
229 |
ENQ(KTM) |
5 | |||||
|
6 |
000110 |
F |
70 |
f |
102 |
|
198 |
|
230 |
АСК(ДА) |
6 | |||||
|
7 |
000111 |
G |
71 |
g |
103 |
|
199 |
|
231 |
BEL(ЗB) |
7 | |||||
|
8 |
001000 |
Н |
72 |
h |
104 |
|
200 |
|
232 |
BS(BШ) |
8 | |||||
|
9 |
001001 |
I |
73 |
i |
105 |
|
201 |
|
233 |
НТ(ГТ) |
9 | |||||
|
10 |
001010 |
J |
74 |
j |
106 |
|
202 |
|
234 |
LF(ПC) |
10 | |||||
|
11 |
001011 |
К |
75 |
k |
107 |
|
203 |
|
235 |
VT(BT) |
11 | |||||
|
12 |
001100 |
L |
76 |
I |
108 |
|
204 |
|
236 |
FF(ПФ) |
12 | |||||
|
13 |
001101 |
М |
77 |
m |
109 |
|
205 |
|
237 |
CR(BK) |
13 | |||||
|
14 |
001110 |
N |
78 |
n |
110 |
|
206 |
|
238 |
SO(BЫX) |
14 | |||||
|
15 |
001111 |
O |
79 |
o |
111 |
|
207 |
|
239 |
SI(BX) |
15 | |||||
|
16 |
010000 |
Р |
80 |
p |
112 |
|
208 |
|
240 |
DLE(AP1) |
16 | |||||
|
17 |
010001 |
Q |
81 |
q |
113 |
|
209 |
|
241 |
DC1(CУ1) |
17 | |||||
|
18 |
010010 |
R |
82 |
r |
114 |
|
210 |
|
242 |
DC2(CУ2) |
18 | |||||
|
19 |
010011 |
S |
83 |
s |
115 |
|
211 |
|
243 |
DС3(СУ3) |
19 | |||||
|
20 |
010100 |
Т |
84 |
t |
116 |
|
212 |
|
244 |
DС4(СУ4) |
20 | |||||
|
21 |
010101 |
U |
85 |
u |
117 |
|
213 |
|
245 |
NAK(HET) |
21 | |||||
|
22 |
010110 |
V |
86 |
v |
118 |
|
214 |
|
246 |
SYN(CИH) |
22 | |||||
|
23 |
010111 |
W |
87 |
w |
119 |
|
215 |
|
247 |
ЕТВ(КБ) |
23 | |||||
|
24 |
011000 |
X |
88 |
x |
120 |
|
216 |
|
248 |
CAN (АН) |
24 | |||||
|
25 |
011001 |
Y |
89 |
y |
121 |
|
217 |
|
249 |
ЕМ(КН) |
25 | |||||
|
26 |
011010 |
Z |
90 |
z |
122 |
|
218 |
|
250 |
SUB(ЗM) |
26 | |||||
|
27 |
011011 |
[ECI] ([ИРК]) |
[ECI] ((ИРК]) |
[ECI] ([ИРК]) |
[ECI] ([ИРК]) |
[ECI] ([ИРК]) | ||||||||||
|
28 |
011100 |
FS (РФ) |
28 |
FS (РФ) |
28 |
FS (РФ) |
28 |
FS (РФ) |
28 |
[Pad] ([ЗАПОЛНИТЕЛЬ]) | ||||||
|
29 |
011101 |
GS (РГ) |
29 |
GS (РГ) |
29 |
GS (РГ) |
29 |
GS (РГ) |
29 |
[Pad] ([ЗАПОЛНИТЕЛЬ]) | ||||||
|
30 |
011110 |
RS (PЗ) |
30 |
RS (PЗ) |
30 |
RS (PЗ) |
30 |
RS (PЗ) |
30 |
ESC |
27 | |||||
|
31 |
011111 |
[NS] ([ЦР]) |
[NS] ([ЦР]) |
[NS] ([ЦР]) |
[NS] ([ЦР]) |
[NS] ([ЦР]) | ||||||||||
|
32 |
100000 |
Space (ПРОБЕЛ) |
32 |
{ |
123 |
|
219 |
|
251 |
FS (РФ) |
28 | |||||
|
33 |
100001 |
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
|
220 |
|
252 |
GS (РГ) |
29 | |||||||
|
34 |
100010 |
" |
34 |
} |
125 |
|
221 |
|
253 |
RS (PЗ) |
30 | |||||
|
35 |
100011 |
# |
35 |
~ |
126 |
|
222 |
|
254 |
US(РИ1) |
31 | |||||
|
36 |
100100 |
$ |
36 |
DEL (ЗБ) |
127 |
|
223 |
|
255 |
{C159} |
159 | |||||
|
37 |
100101 |
% |
37 |
; |
59 |
|
170 |
|
161 |
NBSP(HПP) |
160 | |||||
|
38 |
100110 |
& |
38 |
< |
60 |
¬ |
172 |
|
168 |
|
162 | |||||
|
39 |
100111 |
|
39 |
= |
61 |
± |
177 |
« |
171 |
|
163 | |||||
|
40 |
101000 |
( |
40 |
> |
62 |
|
178 |
- |
175 |
¤ |
164 | |||||
|
41 |
101001 |
) |
41 |
? |
63 |
|
179 |
° |
176 |
|
165 | |||||
|
42 |
101010 |
* |
42 |
[ |
91 |
|
181 |
|
180 |
|
166 | |||||
|
43 |
101011 |
+ |
43 |
\ |
92 |
|
185 |
· |
183 |
§ |
167 | |||||
|
44 |
101100 |
, |
44 |
] |
93 |
° |
186 |
|
184 |
© |
169 | |||||
|
45 |
101101 |
- |
45 |
^ |
94 |
|
188 |
» |
187 |
SHY (ГД) |
173 | |||||
|
46 |
101110 |
. |
46 |
- |
95 |
|
189 |
|
191 |
® |
174 | |||||
|
47 |
101111 |
/ |
47 |
SPACE (ПРОБЕЛ) |
32 |
|
190 |
{С138} |
138 |
¶ |
182 | |||||
|
48 |
110000 |
0 |
48 |
, |
44 |
{C128} |
128 |
{С139} |
139 |
{C149) |
149 | |||||
|
49 |
110001 |
1 |
49 |
. |
46 |
{C129} |
129 |
{С140} |
140 |
{C150} |
150 | |||||
|
50 |
110010 |
2 |
50 |
/ |
47 |
{C130} |
130 |
{С141} |
141 |
{C151} |
151 | |||||
|
51 |
110011 |
3 |
51 |
: |
58 |
(C131} |
131 |
{С142} |
142 |
{C152} |
152 | |||||
|
52 |
110100 |
4 |
52 |
@ |
64 |
{C132} |
132 |
{С143} |
143 |
{C153} |
153 | |||||
|
53 |
110101 |
5 |
53 |
! |
33 |
{C133} |
133 |
{С144} |
144 |
{C154} |
154 | |||||
|
54 |
110110 |
6 |
54 |
| |
124 |
{C134} |
134 |
{С145} |
145 |
{C155} |
155 | |||||
|
55 |
110111 |
7 |
55 |
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
{C135} |
135 |
{С146} |
146 |
{C156} |
156 | ||||||
|
56 |
111000 |
8 |
56 |
[2 Shift A] |
{C136} |
136 |
{С147} |
147 |
{C157} |
157 | ||||||
|
57 |
111001 |
9 |
57 |
[3 Shift A] |
{C137} |
137 |
{С148} |
148 |
{C158} |
158 | ||||||
|
58 |
111010 |
: |
58 |
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
[Latch A] ([ФИКСАТОР А]) |
[Latch A] ([ФИКСАТОР А]) |
[Latch A] ([ФИКСАТОР А]) | |||||||||
|
59 |
111011 |
[Shift В] |
[Shift A] |
Space (ПРОБЕЛ) |
32 |
Space (ПРОБЕЛ) |
32 |
Space (ПРОБЕЛ) |
32 | |||||||
|
60 |
111100 |
[Shift С] |
[Shift С] |
[Lock-In С] ((Блокировка С]) |
[Shift С] |
[Shift С] | ||||||||||
|
61 |
111101 |
[Shift D] |
[Shift D] |
[Shift D] ([РЕГИСТР D]) |
[Lock-In D] ([Блокировка D]) |
[Shift D] | ||||||||||
|
62 |
111110 |
[Shift E] |
[Shift E] |
[Shift E] ([РЕГИСТР E]) |
[Shift E] ([РЕГИСТР E]) |
[Lock-In E] ([Блокировка Е]) | ||||||||||
|
63 |
111111 |
[Latch В] ([ФИКСАТОР В] ]) |
[Latch A] ([ФИКСАТОР А]) |
[Latch В] ([ФИКСАТОР B]) |
[Latch В] ([ФИКСАТОР B]) |
[Latch В] ([ФИКСАТОР В]) | ||||||||||
|
Примечания | ||||||||||||||||
ПРИЛОЖЕНИЕ В
(обязательное)
Структурированное сообщение носителя (режимы 2 и 3)
Режимы 2 и 3 должны быть зарезервированы для использования перевозчиками в транспортной отрасли в качестве символа классификации места назначения.
Настоящее приложение устанавливает структуру первичного сообщения, альтернативные структуры вторичного сообщения как для кодирования, так и для декодирования, а также правила для режимов 2 и 3 при их использовании со структурированным соединением.
Общая структура данных должна соответствовать таблице B.1.
Таблица B.1 - Структурированное сообщение носителя
|
Значение бита |
Кодируемые данные |
Структура |
|
От 6 до 3 |
режим |
двоичная от 0 до 15 |
|
От 36 до 33, от 30 до 7, от 2 до 1 |
Почтовый код |
Цифровой почтовый код (до 9 цифр) |
|
От 42 до 39, от 32 до 31 |
Длина почтового кода |
Только для цифровых почтовых кодов |
|
От 42 до 39, от 36 до 7, от 2 до 1 |
Почтовый код |
Алфавитно-цифровой почтовый код |
|
От 54 до 53, от 48 до 43, от 38 до 37 |
Код названия страны |
Трехразрядный номер по ГОСТ 7.67 |
|
От 60 до 55, от 52 до 49 |
Класс обслуживания |
Трехразрядный номер |
|
От 120 до 61 |
Кодовые слова расширенной коррекции ошибки (EEC) |
|
|
Or 121 до 844 |
Сообщение данных, определенное применением |
|
|
От 625 до 864 |
Кодовые слова стандартной коррекции ошибки (SEC) |
|
|
| ||
B.1 Структура первичного сообщения
Все символы режимов 2 и 3, даже если они являются частью структурированного соединения, должны иметь общую структуру первичного сообщения. Для преобразования данных в значения битов необходимо использовать следующие правила:
1) в первичном сообщении не допускается использовать знаки символики Shift (РЕГИСТР) для перехода от цифрового уплотнения к алфавитному кодированию и обратно;
2) трехразрядный класс обслуживания должен быть представлен двоичным эквивалентом из 10 битов;
3) трехразрядный код названия страны по ГОСТ 7.67 должен быть представлен двоичным эквивалентом из 10 битов;
4) почтовый код представляется 36 битами:
а) при использовании режима 2 шесть битов (с 42-го по 39-й, 32-й и 31-й) кодируют длину (до девяти). Остальные 30 битов являются двоичным представлением цифрового почтового кода. В случае кода страны 840, если "+4" - неизвестен, то почтовый код заполняется нулями;
б) при использовании режима 3 кодируют до шести графических знаков из подмножества кодируемого набора А. Более короткие коды должны быть дополнены пробелами, более длинные коды - усечены;
5) должен быть установлен режим 2, если почтовый код цифровой, и режим 3, если почтовый код алфавитно-цифровой.
|
Пример формирования первичного сообщения: |
|
|
Класс обслуживания: |
999 |
|
Код названия страны по ГОСТ 7.67: |
056 (для Бельгии) |
|
Почтовый код: |
В1050 |
|
Режим 3 |
|
|
Класс 999 преобразуют в двоичное значение: |
1111100111. |
|
Код названия страны 056 преобразуют в двоичное значение: |
111000 |
Добавляют начальные нулевые биты для получения 10-битовой цепочки:
0000111000
Алфавитно-цифровой почтовый код преобразуют в 36-битовую двоичную цепочку, используя кодируемый набор А:
|
|
Кодовое слово |
Двоичное значение |
|
В |
2 |
000010 |
|
1 |
49 |
110001 |
|
0 |
48 |
110000 |
|
5 |
53 |
110101 |
|
0 |
48 |
110000 |
|
Space (ПРОБЕЛ) |
32 |
100000 |
Режим 3 имеет двоичный установочный параметр: 0011
Вся 60-битовая цепочка должна быть преобразована в кодовые слова в соответствии с рисунком B.1.
|
Категория обслуживания |
Код названия страны |
Почтовый код |
Режим | |
|
1111100 |
00 |
0000 |
0011 |
поток битов |
|
55…60 49 |
54 43... 48 37... |
42 31...36 25...30 19...24 13..18 7…12 1.. |
6 |
номера модулей |
Рисунок B.1 - Назначения битов в структурированном сообщении носителя
В.2 Сообщения режимов 2 и 3, начинающиеся с [ )>![]() 01
01![]()
Сообщения, начинающиеся с семи закодированных знаков данных [ )>![]() 01
01![]() *, соответствуют определенным стандартам открытых систем.
*, соответствуют определенным стандартам открытых систем.
______________
* ![]() - международное обозначение управляющего знака RECORD SEPARATOR, русское обозначение и наименование по ГОСТ 27465 - РЗ (РАЗДЕЛИТЕЛЬ ЗАПИСЕЙ).
- международное обозначение управляющего знака RECORD SEPARATOR, русское обозначение и наименование по ГОСТ 27465 - РЗ (РАЗДЕЛИТЕЛЬ ЗАПИСЕЙ).
![]() - международное обозначение управляющего знака GROUP SEPARATOR, русское обозначение и наименование по ГОСТ 27465 - РГ (РАЗДЕЛИТЕЛЬ ГРУПП).
- международное обозначение управляющего знака GROUP SEPARATOR, русское обозначение и наименование по ГОСТ 27465 - РГ (РАЗДЕЛИТЕЛЬ ГРУПП).
Пример сообщения:
[ )> ![]() 01
01![]() 96152382802
96152382802![]() 840
840![]() 001
001![]() 1Z00004951
1Z00004951![]()
UPSN![]() 06X610
06X610![]() 159
159![]() 1234567
1234567![]() 1/1
1/1![]()
![]() Y
Y![]()
634ALPHA DRIVE![]() PITTSBURGH
PITTSBURGH![]() PA
PA![]()
![]() *
*
_____________
* ![]() - международное обозначение управляющего знака END OF TRANSMISSION, русское обозначение и наименование по ГОСТ 27465 - КП (КОНЕЦ ПЕРЕДАЧИ).
- международное обозначение управляющего знака END OF TRANSMISSION, русское обозначение и наименование по ГОСТ 27465 - КП (КОНЕЦ ПЕРЕДАЧИ).
В этом формате за идентификатором [ )>![]() 01
01![]() следует дата (гг), в примере "96".
следует дата (гг), в примере "96".
В.2.1 Кодирование
В сообщениях указанного типа данные кодируют по следующим особым правилам:
1) первые девять знаков данных [ )>![]() 01
01![]() yy извлекают для кодирования во вторичном сообщении;
yy извлекают для кодирования во вторичном сообщении;
2) следующие три элемента данных, представляющие соответственно почтовый код, код названия страны и класс обслуживания и разделители (![]() ) между ними, следующие за годом, извлекают из исходных данных;
) между ними, следующие за годом, извлекают из исходных данных;
3) три знака ![]() (c десятичным значением 29 в версии КОИ-7) исключают из кодирования. Три поля кодируют в первичное сообщение в соответствии с таблицей B.1 и правилами, установленными в B.1;
(c десятичным значением 29 в версии КОИ-7) исключают из кодирования. Три поля кодируют в первичное сообщение в соответствии с таблицей B.1 и правилами, установленными в B.1;
4) оставшуюся цепочку данных кодируют во вторичном сообщении после заголовка [ )>![]() 01
01![]() yy .
yy .
Рекомендуется, чтобы этот конкретный метод для обработки сообщений был бы отделен от применения с целью упрощения требований, предъявляемых к пользователям оборудования, т.е. он должен быть заложен в печатающем устройстве или драйвере печатающего устройства. Образец такого символа MaxiCode приведен на рисунке В.2.

|
Mode 2 (режим 2): 2 | ||
|
Primary (первичное сообщение) | ||
|
|
152382802 | |
|
|
840 | |
|
|
001 | |
|
Secondary (вторичное сообщение): | ||
|
|
[ )> | |
|
|
59 | |
|
|
634ALPHA DR | |
Рисунок В.2 - Пример символа в режиме 2
В.2.2 Декодирование
После декодирования первичного и вторичного сообщений первоначальное сообщение восстанавливают, вставляя три начальных элемента данных, за каждым из которых следует знак ![]() (с десятичным значением 29), в определенном порядке непосредственно за девятью знаками заголовка, начинающего вторичное сообщение. Полное сообщение затем передается как показано в примере сообщения (В.2).
(с десятичным значением 29), в определенном порядке непосредственно за девятью знаками заголовка, начинающего вторичное сообщение. Полное сообщение затем передается как показано в примере сообщения (В.2).
В.3 Сообщения режимов 2 и 3, не начинающиеся с [)> ![]() 01
01![]()
В режимах 2 и 3 первичные сообщения всегда содержат специальные данные и кодируют почтовый код, код названия страны и класс обслуживания. Эти элементы данных вместе с содержимым вторичного сообщения должны поступать в схему кодирования в виде, позволяющем отличать их друг от друга. Три элемента первичных данных должны поступать в указанной последовательности с разделителем ![]() (десятичное значение 29) непосредственно за содержимым вторичного сообщения. Каждый элемент данных должен быть надлежащего типа, т.е. почтовые коды в режиме 2 должны быть целиком цифровыми. Тогда стандартный формат сообщения представляет собой:
(десятичное значение 29) непосредственно за содержимым вторичного сообщения. Каждый элемент данных должен быть надлежащего типа, т.е. почтовые коды в режиме 2 должны быть целиком цифровыми. Тогда стандартный формат сообщения представляет собой:
почтовый_код![]() код_названия_страны
код_названия_страны![]() класс_обслуживания
класс_обслуживания![]() вторичное_
вторичное_
сообщение![]() .
.
Пример сообщения:
524032140![]() 840
840![]() 001
001![]() AIM USA
AIM USA![]() 634 ALPHA DRIVE
634 ALPHA DRIVE![]()
PITTSBURGH![]() PA
PA![]()
В.3.1 Кодирование
Первые три элемента данных - почтовый код, код названия страны и класс обслуживания соответственно - разделены знаком![]() (с десятичным значением 29). Эти элементы данных кодируют в первичном сообщении, как указано в B.1. Остальную часть сообщения:
(с десятичным значением 29). Эти элементы данных кодируют в первичном сообщении, как указано в B.1. Остальную часть сообщения:
AIM USA![]() 634 ALPHA DRIVE
634 ALPHA DRIVE![]() PITTSBURGH
PITTSBURGH![]()
![]()
кодируют во вторичном сообщении.
В.3.2 Декодирование
После декодирования первичного и вторичного сообщений первоначальное сообщение восстанавливают вставляя три начальных элемента данных, за каждым из которых следует знак ![]() (с десятичным значением 29), в определенном порядке непосредственно перед цепочкой вторичного сообщения. Полное сообщение затем передается как показано в примере сообщения.
(с десятичным значением 29), в определенном порядке непосредственно перед цепочкой вторичного сообщения. Полное сообщение затем передается как показано в примере сообщения.
В.4 Режимы 2 и 3 и структурированное соединение
Основные правила для структурированного соединения и режимов 2 и 3 установлены в 4.9.2. Дополнительные рекомендации приведены в В.4.1 и В.4.2.
В.4.1 Рекомендации по кодированию
Первичное сообщение (кодирование почтового кода, кода названия страны и класса обслуживания) должно повторяться в каждом последующем символе режима 2 или 3.
Следовательно, с учетом кодовых слов структурированного соединения для вторичного сообщения можно использовать только кодовые слова, начинающиеся с ![]() .
.
В.4.2 Рекомендации по декодированию
При использовании структурированного соединения вместе с символами режимов 2 и 3 первичное сообщение можно декодировать, начиная с любого символа структурированного соединения.
Если устройство считывания обнаружило символ режима 2 или 3 вместе с индикатором структурированного соединения в первых двух позициях вторичного сообщения, устройство считывания должно восстановить целое сообщение данных двумя способами:
Способ А. Если данные [ )>![]() 01 декодированы из кодовых слов с
01 декодированы из кодовых слов с ![]() по
по ![]() (т.е. из позиций с 3 по 10 вторичного сообщения) первого символа:
(т.е. из позиций с 3 по 10 вторичного сообщения) первого символа:
1) декодируют первый символ в соответствии с В.2.2;
2) декодируют последовательность символов, начиная с кодового слова ![]() и далее, игнорируя данные первичного сообщения;
и далее, игнорируя данные первичного сообщения;
3) восстанавливают данные в следующей последовательности:
a) заголовок формата [ )>![]() 01
01![]() yy;
yy;
b) данные первичного сообщения с тремя знаками ![]() , восстановленными с надлежащих позиций;
, восстановленными с надлежащих позиций;
c) данные вторичного сообщения из первого символа структурированного соединения;
d) данные из следующего вторичного сообщения (сообщений);
Способ В. Если данные [ )>![]() 01 не декодированы из кодовых слов с
01 не декодированы из кодовых слов с ![]() по
по ![]() (т.е. из позиций с 3 по 10 вторичного сообщения) первого символа:
(т.е. из позиций с 3 по 10 вторичного сообщения) первого символа:
1) декодируют первый символ в соответствии с рекомендациями В.3.2;
2) декодируют последовательность символов из кодовых слов, начиная с кодового слова ![]() и далее, игнорируя данные первичного сообщения;
и далее, игнорируя данные первичного сообщения;
3) восстанавливают данные в следующей последовательности:
a) данные первичного сообщения с тремя знаками ![]() , восстановленными с надлежащих позиций;
, восстановленными с надлежащих позиций;
b) данные вторичного сообщения из первого символа структурированного соединения;
c) данные из следующего вторичного сообщения (сообщений).
Знак-разделитель ![]() (с десятичным значением 29) должен следовать за каждым элементом данных, затем это сообщение должно быть передано в качестве потока знаков КОИ-7.
(с десятичным значением 29) должен следовать за каждым элементом данных, затем это сообщение должно быть передано в качестве потока знаков КОИ-7.
Во всех иных случаях передаваемое сообщение должно представлять собой поток знаков КОИ-7, составленный из почтового кода, кода названия страны, класса обслуживания и вторичного сообщения в указанном порядке.
ПРИЛОЖЕНИЕ С
(обязательное)
Руководство по качеству печати двумерного символа матричной символики
В настоящем приложении приведено описание последовательности действий для оценки качества печати двумерного символа матричной символики, которое может быть адаптировано для любой матричной символики. Указанный метод во многом совпадает с руководством [6] по оценке качества печати символов линейного штрихового кода. Он начинается с получения черно-белого изображения символа с высоким разрешением, управляемого при условиях освещения и наблюдения. Анализируют следующие параметры сохраненного изображения: декодирование, контраст символа, изменение "печати", осевую неоднородность и неиспользованную коррекцию ошибки. Окончательной оценкой символа является значение наименьшего класса среди пяти перечисленных параметров и любых иных, установленных для данной символики или применения.
Представленные в настоящем приложении процедуры должны быть обязательно дополнены рекомендуемым алгоритмом декодирования и другими элементами измерений в пределах требований к символике. Эти процедуры могут быть изменены или отменены в соответствии с действующими требованиями к символике или применению.
C.1 Получение изображения для испытаний
Изображение символа для испытаний должно быть получено в конфигурации, имитирующей типичную ситуацию сканирования данного символа, но с более высоким разрешением, однородным освещением и лучшей фокусировкой. Специализированные применения должны точно регламентировать цвет, угол освещения символа, а также требования к разрешению изображения, но следующие общие схемы испытаний должны соответственно действовать во многих открытых применениях.
Стандартная монохромная видеокамера должна отображать проверяемый символ непосредственно по оси с его центром и нормалью к его поверхности. Используемые линзы должны соответствовать границам всего символа (включая необходимые свободные зоны) в достаточной фокусировке и с достаточно малым полем обзора, чтобы минимизировать оптические искажения. Слабое световое излучение должно однородно освещать область символа хотя бы с двух направлений под углом падения 45°. Проверяемые изображения могут быть переведены с помощью 8-битового черно-белого преобразования в цифровую форму с использованием стандартного оборудования захвата кадров, а полутоновая шкала должна быть откалибрована использованием меток с известным диффузионным коэффициентом отражения.
Независимо от точных оптических установок выбор должен определяться двумя принципами:
- черно-белое проверяемое изображение должно быть номинально линейным и не должно корректироваться в любую сторону, как для усиления контраста, так и для улучшения внешнего вида;
- разрешение изображения должно быть достаточным для совершения однообразных считываний, т.е модуль по длине и по высоте должен охватывать хотя бы пять пикселей изображения.
С.2 Оценка параметров символа
С.2.1 Декодирование
К изображению для испытаний должен быть применен рекомендуемый алгоритм декодирования символики. При успешном выполнении декодирование соответствует классу А (4.0), в противном случае - классу F (0.0).
Параметры декодирования оценивают по принципу да/нет, основанному на том, все ли параметры оптимально отображенного символа достаточно хороши для считывания. Помимо этого, начальное рекомендуемое декодирование решает три дополнительные задачи, необходимые для последующего измерения других параметров качества символа. Во-первых, определяют местоположение и область, занимаемую проверяемым символом в изображении. Во-вторых, применительно к обстоятельствам создают схему расположения координатной сетки центров модулей данных для их выбора. В-третьих, исправляют ошибку и определяют, использовало ли повреждение символа какой-либо резерв ошибки. Как изображения, так и координаты изображения и декодирование ошибки способствуют одному или более из следующих измерений.
С.2.2 Контраст символа
Внутри черно-белого изображения, расширенного до границ любой требуемой свободной зоны, все пиксели изображения, находящиеся в области проверяемого символа, должны быть классифицированы по значениям коэффициента отражения для выбора 10% наиболее темных пикселей и 10% наиболее светлых пикселей. Вычисляют среднее арифметическое значение коэффициента отражения 10% наиболее темных и среднее арифметическое значение коэффициента отражения 10% наиболее светлых модулей. Разность двух средних арифметических значений определяет контраст символа (Symbol Contrast - SC).
Класс контраста символа оценивается следующим образом:
А (4,0) - SC![]() 70%;
70%;
В (3,0) - SC![]() 55%;
55%;
С (2,0) - SС![]() 40%;
40%;
D (1,0) - SC![]() 20%;
20%;
F (0,0) - SC<20%,
По контрасту символа оценивают, являются ли два состояния отражения символа, называемые светлым и темным, достаточно и единообразно отличными по всей площади символа.
С.2.3 Изменение печати
Для оценки изменения печати вычисляют порог коэффициента отражения как среднее между средней величиной для темных и средней величиной для светлых в соответствии с С.2.2. С использованием порога формируют вторичное двоичное изображение, различающее темные и светлые области.
Параметр изменения печати - это степень соответствующего заполнения темными или светлыми метками границ своего модуля - это важный фактор, свидетельствующий о качестве процесса, влияющий на эффективность считывания. Определенные графические структуры, наиболее показательные по элементному увеличению или уменьшению относительно номинальных размеров, сильно различаются между символиками и должны быть определены в спецификациях, но в общем могут являться как фиксированными структурами, так и изолированным(и) элементом(ми), размер(ы) которого(рых) ![]() определяется(ются) подсчетом пикселей двоичного оцифрованного изображения и округляется(ются). Можно независимо установить и проверить более одного размера, например горизонтальное и вертикальное изменение. Для каждого проверяемого размера должны быть определены как номинальное значение
определяется(ются) подсчетом пикселей двоичного оцифрованного изображения и округляется(ются). Можно независимо установить и проверить более одного размера, например горизонтальное и вертикальное изменение. Для каждого проверяемого размера должны быть определены как номинальное значение ![]() , так и дополнительное максимальное
, так и дополнительное максимальное ![]() или минимальное
или минимальное ![]() значение. Каждый измеряемый размер
значение. Каждый измеряемый размер ![]() должен быть нормализован по отношению к соответствующим номинальному и предельным значениям:
должен быть нормализован по отношению к соответствующим номинальному и предельным значениям:
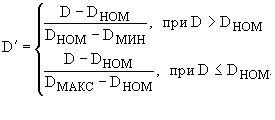
Изменение печати оценивается следующим образом:
|
класс А (4,0) |
- при |
-0,50 | |
|
класс В (3,0) |
- при |
-0,70 | |
|
класс С (2,0) |
- при |
-0,85 | |
|
класс D (1,0) |
- при |
-1,00 | |
|
класс F (0,0) |
- при |
|
С помощью изменения печати проверяют увеличение или уменьшение от номинальных значений графических свойств символа настолько, чтобы затруднить считываемость изображений, полученных в менее оптимальных условиях, чем условия испытаний.
С.2.4 Осевая неоднородность
Двумерные матричные символы включают поля данных для модулей, номинально лежащих в геометрически правильной многоугольной сетке. Любой рекомендуемый алгоритм декодирования должен применительно к ситуации отображать местонахождение центров этих модулей для извлечения данных. С помощью осевой неоднородности измеряют и оценивают интервал между отображенными центрами, т.е. выборочные точки в направлении каждой из основных осей сетки.
Интервалы между соседними выборочными точками независимым образом сортируют для каждой многоугольной оси, затем вычисляют средний промежуток ![]() вдоль каждой оси. Осевая неоднородность (Axial Nonuninformity - AN) - мера отличия числа интервалов между выборочными точками от одной оси к другой, а именно:
вдоль каждой оси. Осевая неоднородность (Axial Nonuninformity - AN) - мера отличия числа интервалов между выборочными точками от одной оси к другой, а именно:
![]() ,
,
где abs() абсолютное значение. Если символика имеет более двух основных осей, тогда AN высчитывают для двух наиболее отличающихся средних интервалов. Осевую неоднородность оценивают следующим образом:
|
класс А (4,0) - |
при AN | |
|
класс В (3,0) - |
при AN | |
|
класс С (2,0) - |
при AN | |
|
класс D(1,0) - |
при AN | |
|
класс F (0,0) - |
при AN>0,12. |
С помощью осевой неоднородности проверяют символ на нечетное масштабирование, препятствующее считываемости под некоторым углом зрения, не являющимся нормальным, больше чем другие.
С.2.5 Неиспользованная коррекция ошибок
Возможность коррекции декодирования Рида-Соломона выражается неравенством:
![]() ,
,
где ![]() - число стираний;
- число стираний;
![]() - число ошибок подстановки знака;
- число ошибок подстановки знака;
![]() - число кодовых слов коррекции ошибок;
- число кодовых слов коррекции ошибок;
![]() - число кодовых слов, зарезервированных для обнаружения ошибок.
- число кодовых слов, зарезервированных для обнаружения ошибок.
Значения ![]() и
и ![]() определяются спецификацией символики (обычно в зависимости от размера символа), а
определяются спецификацией символики (обычно в зависимости от размера символа), а ![]() и
и ![]() определяются во время успешно проведенного рекомендуемого декодирования. Значение неиспользованной коррекции ошибок (Unused Error Correction - UEC) вычисляют по формуле
определяются во время успешно проведенного рекомендуемого декодирования. Значение неиспользованной коррекции ошибок (Unused Error Correction - UEC) вычисляют по формуле
![]() .
.
В символах с количеством блоков Рида-Соломона более одного (т.е. чередующихся) UEC вычисляют независимо для каждого блока, затем наименьшее значение оценивают следующим образом:
|
класс А (4,0) - |
при UEC | |
|
класс В (3,0) - |
при UEC | |
|
класс С (2,0) - |
при UEC | |
|
класс D (1,0) - |
при UEC | |
|
класс F (0,0) - |
при UEC<0,25. |
С помощью параметра неиспользованной коррекции ошибок проверяют, до какой степени повреждение области или ячейки символа разрушает запас надежности считывания, обеспеченный коррекцией ошибок.
С.3 Полный класс символа
Полный класс символа соответствует наименьшему из вышеуказанных классов параметров. В таблице C.1 приведены все оцениваемые параметры и их классы.
Таблица C.1 - Параметры качества печати двумерного штрихового кода
|
Класс параметра |
Рекомендуемое декодирование |
Контраст символа |
Изменение печати |
Осевая неоднородность |
Неиспользуемая коррекция ошибок |
|
А (4,0) |
Успешно |
SC |
-0,50 |
AN |
UEC |
|
В (3,0) |
|
SC |
-0,70 |
AN |
UEC |
|
С (2,0) |
|
SC |
-0,85 |
AN |
UEC |
|
D (1,0) |
|
SC |
-1,00 |
AN |
UEC |
|
F (0,0) |
Отсутствует |
SC<20% |
|
AN>0,12 |
UEC<0,25 |
ПРИЛОЖЕНИЕ D
(обязательное)
Алгоритм исправления ошибок
Приведенный расчет соответствует алгоритму Питерсона-Горенштейна-Зайлера (Peterson-Gorenstein-Zierler Algorithm), который исправляет ошибки, используя кодовые слова с исправлением ошибок Рида-Соломона. Стирания исправляют как ошибки начальным заполнением любых позиций стертого знака фиктивными значениями.
Все вычисления проводят с использованием арифметических операций поля Галуа GF(64). Сложение и вычитание эквивалентны двоичным операциям исключающего ИЛИ. Умножение и деление может быть произведено с использованием таблиц логарифмов и антилогарифмов. Подпрограмма для генерации этих таблиц является частью программы исправления ошибок MaxiCode, находящейся на дискете разработчиков MaxiCode [5].
Создают полином знаков символа:
![]() ,
,
где ![]() - первый знак символа,
- первый знак символа, ![]() - общее число знаков символа.
- общее число знаков символа.
Рассчитывают ![]() значений синдрома от
значений синдрома от ![]() до
до ![]() вычислением
вычислением ![]() при
при ![]() , для
, для ![]() от 1 до
от 1 до ![]() , где
, где ![]() - число кодовых слов коррекции ошибок в символе.
- число кодовых слов коррекции ошибок в символе.
Формируют и решают систему из ![]() уравнений с
уравнений с ![]() неизвестными от
неизвестными от ![]() до
до ![]() , используя
, используя ![]() синдромов:
синдромов:
![]()
![]()
:
:
![]() ,
,
где ![]() .
.
Создают полином местоположения ошибок:
![]()
из ![]() значений
значений ![]() , полученных выше.
, полученных выше.
Вычисляют ![]() , при
, при ![]() для
для ![]() от 0 до
от 0 до ![]() , где
, где ![]() - общее число знаков символа в символе. Если
- общее число знаков символа в символе. Если ![]() , местоположение ошибки считается
, местоположение ошибки считается ![]() . Если найдено более
. Если найдено более ![]() местоположений ошибок, то символ невозможно исправить.
местоположений ошибок, то символ невозможно исправить.
Местоположения ошибок хранят в ![]() переменных местоположения ошибок от
переменных местоположения ошибок от ![]() до
до ![]() , где
, где ![]() - число найденных местоположений ошибок. Формируют и решают систему из
- число найденных местоположений ошибок. Формируют и решают систему из ![]() уравнений с
уравнений с ![]() неизвестными от
неизвестными от ![]() до
до ![]() (величины ошибок), используя переменные местоположения ошибок
(величины ошибок), используя переменные местоположения ошибок ![]() и первые
и первые ![]() синдромов
синдромов ![]() :
:
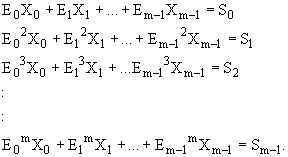
Складывают значения ошибок от ![]() до
до ![]() со значениями знаков символа в соответствующих местах расположения ошибки от
со значениями знаков символа в соответствующих местах расположения ошибки от ![]() до
до ![]() для исправления ошибок.
для исправления ошибок.
Этот алгоритм, написанный на С, находится на дискете [5].
ПРИЛОЖЕНИЕ Е
(обязательное)
Идентификаторы символики
В ГОСТ Р 51294.1* приведена общая методология определения считанной символики, набор вариантов обработки, устанавливаемых в устройстве считывания, и иные специальные параметры обнаруженной символики.
____________
* В ИСО/МЭК 16023 дана ссылка на [6], на основе которого разработан ГОСТ Р 51294.1
Для MaxiCode установлен идентификатор символики:
]Um,
где ] - знак флага идентификатора символики (знак версии КОИ-7 с десятичным значением 93);
U - знак кода для идентификации символики MaxiCode;
m - знак-модификатор с одним из значений, приведенных в таблице E.1.
Таблица E.1 - Значения вариантов идентификатора символики для MaxiCode
|
Значение варианта |
Вариант обработки |
|
0 |
Символ в режиме 4 или 5 |
|
1 |
Символ в режиме 2 или 3 |
|
2 |
Символ в режиме 4 или 5 с поддержкой протокола ECI |
|
3 |
Символ в режиме 2 или 3 с поддержкой протокола ECI во вторичном сообщении (сообщениях) |
|
Примечание - Допустимые значения для | |
ПРИЛОЖЕНИЕ F
(рекомендуемое)
Использование знаков Numeric Shift (ЦИФРОВОЙ РЕГИСТР),
Shift (РЕГИСТР), Latch (ФИКСАТОР), Lock-In (БЛОКИРОВКА)
Оптимальная эффективность кодирования может быть достигнута при использовании следующих рекомендаций. Исходная программа на С, записанная на дискете [5], позволяет как кодировать сообщение с учетом настоящих рекомендаций, так и декодировать сообщение.
F.1 Знак Numeric Shift (ЦИФРОВОЙ РЕГИСТР)
Если в цепочке встречается 9 или более цифр, рекомендуется использовать знак [NS] (ЦР]) следующим образом:
1) кодируют знак [NS];
2) выделяют в цепочке первый 9-разрядный блок;
3) осуществляют преобразование 9-разрядного десятичного числа в 30-битовое двоичное значение. Если число бит двоичной цепочки менее 30, то следует прибавить соответствующее число незначимых нулевых битов в позиции старшего порядка цепочки;
4) если осталось 9 или более цифр, продолжают действия, начиная с шага 1, в противном случае кодируют любые оставшиеся цифры как знаки кодируемого набора А.
Пример:
Десятичное значение: 123456789
Двоичный эквивалент (первым следует бит старшего порядка):
111010110111100110100010101
Добавление нулей:
000111010110111100110100010101
|
Модули знака символа: |
Кодовые слова: | |
|
000111 |
7 | |
|
010110 |
22 | |
|
111100 |
60 | |
|
110100 |
52 | |
|
010101 |
21 |
F.2 Переход от кодируемого набора А к кодируемому набору В
Если при использовании знаков набора А последующие знаки содержатся только в наборе В, необходимо поменять кодируемый набор следующим образом:
1) используют знак [Latch В] ([ФИКСАТОР В]), если следующие два или более знаков принадлежат кодируемому набору В;
2) используют знак [Shift В] ([РЕГИСТР В]), если только один следующий знак принадлежит кодируемому набору В.
F.3 Переход от кодируемого набора В к кодируемому набору А
Если при использовании знаков набора В последующие знаки содержатся только в наборе А, необходимо поменять кодируемый набор.
Примечание - Пять специальных графических знаков (знаки пунктуации версии КОИ-7 с десятичными значениями 32, 44, 46, 47 и 58) присутствуют в обоих кодируемых наборах. В зависимости от следующих знаков данных наиболее эффективное кодирование обеспечивается следующими особыми знаками перехода:
1) используют знак [NS] ([ЦР]), если следующие девять или более знаков являются цифровыми (детальные рекомендации приведены в F.1);
2) используют знак [Latch А] ([ФИКСАТОР А]), если следующие четыре или более знаков присутствуют в наборе А;
3) используют [3 Shift A] ([3 РЕГИСТР А]), если следующие три знака присутствуют в наборе А;
4) используют [2 Shift A] ([2 РЕГИСТР А]), если следующие два знака присутствуют в наборе А;
5) используют [Shift А] ([РЕГИСТР А]), если один следующий знак присутствует в наборе А, а остальные данные - в наборе В.
F.4 Использование знака Lock-In (БЛОКИРОВКА) для перехода к кодируемым наборам С, D или Е
Если при использовании знаков кодируемых наборов А или В последующие знаки содержатся только в наборах С, D или Е, переход к соответствующим знакам осуществляется следующим образом:
1) используют соответствующий знак [Shift С, D или Е] ([РЕГИСТР С, D или Е]);
2) кодируют соответствующий знак [Lock-In С, D или Е] ([БЛОКИРОВКА С, D или Е]);
3) кодируют знаки данных из выбранного кодируемого набора;
4) если в конце кодирования необходимо перейти к другому кодируемому набору:
a) если знаки присутствуют в кодируемом наборе А или В, используют соответствующий [Latch А или В] ([ФИКСАТОР А или В]);
b) если знаки присутствуют в кодируемом наборе С, D или Е, используют [Shift С, D или Е] ([РЕГИСТР С, D или Е]) для кодирования одного знака или [Shift С, D или Е] ([РЕГИСТР С, D или Е]) и соответствующий знак [Lock-In] ([БЛОКИРОВКА]) для кодирования большего количества знаков.
F.5 Пример
Кодирование текста, состоящего из четырех строк данных, с использованием правил перехода для минимизации протяженности, можно проиллюстрировать следующим образом:
|
Данные |
Число знаков данных |
|
|
32 |
|
rue de Stassart 36 |
18 |
|
B-1050 BRUXELLES |
16 |
|
TEL+3225196811 |
15 |
|
ВСЕГО |
81 |
Для простоты пояснения кодовые слова не показаны, для эффективности переключения использовать только кодируемые данные и управляющие знаки символики.
|
Данные и знаки символики |
Число кодовых слов |
|
C[Latch B]omit[Shift D] |
|
|
[Shift A]Europ[Shift D] |
|
|
Normalization{FS} |
38 |
|
rue |
21 |
|
B-1050 |
17 |
|
TEL |
12 |
|
ВСЕГО |
88 |
Обозначения:
![]() - знак данных для пробела;
- знак данных для пробела;
[ ] - управляющий знак символики;
{FS} - управляющий знак КОИ-7 - FILE SEPARATOR*;
_____________
* Русское обозначение и наименование знака по ГОСТ 27465 - {РФ} РАЗДЕЛИТЕЛЬ ФАЙЛОВ.
bbbbb - пять кодовых слов, использованных для цифрового уплотнения.
ПРИЛОЖЕНИЕ G
(рекомендуемое)
Рекомендации по кодированию данных с учетом емкости символа
В любом применении следует помнить, что символика MaxiCode содержит параметры, позволяющие использовать ее при высокоскоростном всенаправленном сканировании с большей емкостью данных, чем у линейной символики штрихового кода, но с меньшей емкостью, чем у некоторых других двумерных символик. Эти свойства (4.1.1 и 4.1.2) должны учитываться при разработке любого применения.
Рекомендации для достижения емкости для кодирования одного или более символов MaxiCode, допустимых для применения, разработаны для трех категорий пользователей:
- производителей принтеров или поставщиков программного обеспечения для печати, разрабатывающих алгоритмы дизайна символа;
- разработчиков стандартов, регламентирующих применение для того, чтобы они могли убедиться в том, что параметры дизайна обеспечивают приемлемое решение;
- пользователей, имеющих определенные ограничения, которые должны быть удовлетворены. Предполагается, что оборудование и программное обеспечение для печати содержат определяемые пользователем параметры для автоматического и надлежащего производства символов MaxiCode.
При кодировании данных с учетом емкости символа следует учитывать:
1) максимальное число кодовых слов в символе от 93 до 77 в зависимости от выбранного уровня коррекции ошибки;
2) если все данные, подлежащие кодированию, присутствуют в интерпретации по умолчанию и содержатся в кодируемом наборе А, то данные кодируют в кодовые слова в соотношении 1:1;
3) если цифровые данные состоят из 9 или более разрядов, использование знака [NS] ([ЦР]) увеличивает емкость кодируемых данных. Например, если все кодируемые данные являются цифровыми, может быть закодировано 138 или 113 цифр в зависимости от выбранного уровня коррекции ошибки;
4) если используется интерпретация по умолчанию, а данные требуют использования кодируемых наборов от В до Е, необходим переход, для которого расходуется некоторое количество кодовых слов;
5) если применение поддерживает протоколы интерпретации расширенного канала (ECI), то переход к другой интерпретации расширенного канала (ECI), требующий двух или более кодовых слов, может оказаться более эффективным, чем использование интерпретации по умолчанию;
6) следует учитывать дополнительные требования для соответствия требованиям стандартов, регламентирующих конкретное применение (например использование определенного синтаксиса и т.д.).
Если данные не могут быть закодированы в требуемом числе символов MaxiCode, программное обеспечение для печати должно обеспечить некоторый выход пользователю для пересмотра параметров:
1) использование большего числа символов в структурированном соединении до максимально возможного - восьми символов;
2) уменьшение коррекции ошибок с более высокого на более низкий уровень;
3) в крайних случаях, пересмотр содержимого данных.
ПРИЛОЖЕНИЕ Н
(справочное)
Пример кодирования MaxiCode
Настоящее приложение рассматривает процесс кодирования короткого сообщения "MaxiCode (19 chars)" в символ MaxiCode двумя способами: для увеличения структурированного сообщения носителя в режимах 2 и 3 или в качестве полного сообщения, закодированного в режимах с 3 по 5.
Существуют четыре основных этапа кодирования, два из которых приведены в таблице H.1. Входное сообщение расценивается как последовательность из 19 знаков данных версии КОИ-7 по ИСО 646, которые определены с m1 no m19 (в графе "Обозначение данных" таблицы H.1).
Таблица H.1 - Кодирование кодовых слов и знаков символа для "MaxiCode (19 chars)"
|
|
|
|
|
Режимы 2 и 3 |
Режимы 4, 5 и 6 | |||||||
|
Обозначение данных |
Исходные знаки |
Кодовые слова |
Знак символа |
Подмножество КO* |
Знак символа |
Подмножество КО* | ||||||
|
|
|
Обозна- чение |
Значение |
|
П |
ВНЧ |
ВЧ |
|
П |
ВНЧ |
ВЧ | |
|
|
M |
|
13 |
|
|
|
|
|
|
|
| |
|
|
Latch В |
|
63 |
|
|
|
|
|
|
|
| |
|
|
A |
|
1 |
|
|
|
|
|
|
|
| |
|
|
X |
|
24 |
|
|
|
|
|
|
|
| |
|
|
I |
|
9 |
|
|
|
|
|
|
|
| |
|
|
Shift A |
|
59 |
|
|
|
|
|
|
|
| |
|
|
С |
|
3 |
|
|
|
|
|
|
|
| |
|
|
О |
|
15 |
|
|
|
|
|
|
|
| |
|
|
D |
|
4 |
|
|
|
|
|
|
|
| |
|
|
E |
|
5 |
|
|
|
|
|
|
|
| |
|
|
Space |
|
47 |
|
|
|
|
|
|
|
| |
|
|
3 Shift A |
|
57 |
|
|
|
|
|
|
|
| |
|
|
( |
|
40 |
|
|
|
|
|
|
|
| |
|
|
1 |
|
49 |
|
|
|
|
|
|
|
| |
|
|
9 |
|
57 |
|
|
|
|
|
|
|
| |
|
|
Space |
|
47 |
|
|
|
|
|
|
|
| |
|
|
С |
|
3 |
|
|
|
|
|
|
|
| |
|
|
Н |
|
8 |
|
|
|
|
|
|
|
| |
|
|
А |
|
1 |
|
|
|
|
|
|
|
| |
|
|
R |
|
18 |
|
|
|
|
|
|
|
| |
|
|
S |
|
19 |
|
|
|
|
|
|
|
| |
|
|
Shift A |
|
59 |
|
|
|
|
|
|
|
| |
|
|
) |
|
41 |
|
|
|
|
|
|
|
| |
|
|
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
|
33 |
|
|
|
|
|
|
|
| |
|
|
[Pad] ([ЗАПОЛНИТЕЛЬ]) |
|
33 |
|
|
|
|
|
|
|
| |
|
|
: |
: |
: |
: |
|
: |
: |
: |
: |
|
| |
|
* Подмножества коррекции ошибок - КО: П - первичное, ВНЧ - вторичное нечетное, ВЧ - вторичное четное. | ||||||||||||
Этап 1 - Создание последовательности кодовых слов данных
Первый этап является общим и независимым от планируемого режима символа. Используя значения из таблицы приложения А, знаки данных перемежаются командами переключения кодируемых наборов [Shift] ([РЕГИСТР]) и [Latch] ([ФИКСАТОР]), что создает эквивалентную последовательность кодовых слов oт ![]() до
до ![]() , как показано в таблице H.1.
, как показано в таблице H.1.
Кодирование сообщения "MaxiCode" начинается с кодируемого набора А таким образом, что первый знак "М" кодируется значением 13 (![]() ). Так как следующие знаки сообщения - строчные, необходимо перейти, используя знак [Latch], к кодируемому набору В (
). Так как следующие знаки сообщения - строчные, необходимо перейти, используя знак [Latch], к кодируемому набору В (![]() ), в котором кодируют следующие 3 буквы (с
), в котором кодируют следующие 3 буквы (с ![]() по
по ![]() ). Так как за прописной буквой С сразу следуют строчные буквы, перед прописной С используют временный переход к кодируемому режиму А (знак [Shift] (
). Так как за прописной буквой С сразу следуют строчные буквы, перед прописной С используют временный переход к кодируемому режиму А (знак [Shift] (![]() ), затем кодирование автоматически возвращается обратно к кодируемому набору В на следующие четыре знака (с
), затем кодирование автоматически возвращается обратно к кодируемому набору В на следующие четыре знака (с ![]() по
по ![]() ). Далее используют [Triple Shift A] ([РЕГИСТР НА ТРИ A]) (
). Далее используют [Triple Shift A] ([РЕГИСТР НА ТРИ A]) (![]() ) для кодирования трех знаков данных (с
) для кодирования трех знаков данных (с ![]() по
по ![]() ) в кодируемом наборе А, затем кодирование снова возвращается к кодируемому набору В для кодирования следующих шести знаков (с
) в кодируемом наборе А, затем кодирование снова возвращается к кодируемому набору В для кодирования следующих шести знаков (с ![]() по
по ![]() ). В завершение необходим еще один временный переход к кодируемому набору А (знак [Shift]) (
). В завершение необходим еще один временный переход к кодируемому набору А (знак [Shift]) (![]() ) для кодирования правой круглой скобки в данных сообщения.
) для кодирования правой круглой скобки в данных сообщения.
Рекомендации по выбору команд [Shift] и [Latch] для эффективной компоновки сообщений в последовательность кодовых слов приведены в приложении F. Окончательным результатом кодирования сообщения является последовательность кодовых слов, которая длиннее, чем первоначальное сообщение данных, но, как правило, короче необходимой для заполнения области данных символа MaxiCode. При необходимости к окончанию последовательности кодовых слов добавляют кодовые слова [Pad] ([ЗАПОЛНИТЕЛЬ]) для заполнения всех позиций знаков символов данных в символе.
Этап 2 - Присвоение кодовых слов позициям знаков символа
Число кодовых слов данных в символе MaxiCode и их расположение определяет пользователь. Во-первых, пользователь может выбрать отведение области первичного сообщения MaxiCode под структурированное сообщение носителя (режимы 2 и 3), в связи с чем для цепочки кодовых слов данных вместе со стандартной коррекцией ошибок останется доступной только область вторичного сообщения.
Во-вторых, первичное сообщение может быть использовано для увеличения емкости сообщения, тогда пользователь может выбрать во вторичном сообщении как стандартный (режимы 4 и 6), так и расширенный режимы коррекции ошибок. Присвоения знаков символа ![]() приведены в таблице H.1 для обоих случаев, где N соответствуют точным позициям знаков, изображенных на рисунке 4.
приведены в таблице H.1 для обоих случаев, где N соответствуют точным позициям знаков, изображенных на рисунке 4.
Выбор режима символа (таблица 4) всегда отражается в четырех битах младшего порядка знака символа ![]() . Существуют два различных случая присвоения кодовых слов (режимы 2 и 3 или 4-6):
. Существуют два различных случая присвоения кодовых слов (режимы 2 и 3 или 4-6):
a) Режимы 2 и 3
Структурированное сообщение носителя в режимах 2 и 3 заполняет знаки символа с ![]() по
по ![]() плюс два бита старшего порядка из
плюс два бита старшего порядка из ![]() , вместе с уплотненными данными о месте назначения, как указано в приложении В. Таким образом, последовательность кодовых слов для данных сообщения размещается исключительно во вторичном сообщении, как показано в графе "Режимы 2 и З" таблицы H.1 (от
, вместе с уплотненными данными о месте назначения, как указано в приложении В. Таким образом, последовательность кодовых слов для данных сообщения размещается исключительно во вторичном сообщении, как показано в графе "Режимы 2 и З" таблицы H.1 (от ![]() и далее до
и далее до ![]() ). Для исправления ошибок (этап 3) кодовые слова вторичного сообщения разделены на нечетные и четные чередующиеся подмножества, обозначенные соответственно
). Для исправления ошибок (этап 3) кодовые слова вторичного сообщения разделены на нечетные и четные чередующиеся подмножества, обозначенные соответственно ![]() и
и ![]() . Из таблицы H.1 следует, что с кодового слова
. Из таблицы H.1 следует, что с кодового слова ![]() , соответствующего букве М, начинается нечетное подмножество, а с кодового слова
, соответствующего букве М, начинается нечетное подмножество, а с кодового слова ![]() , [Latch В] ([ФИКСАТОР В]) - четное подмножество.
, [Latch В] ([ФИКСАТОР В]) - четное подмножество.
b) Режимы 4, 5 и 6
В режимах с 4-го по 6-й знак символа ![]() хранит только значение режима, а следующие девять кодовых слов данных первичного сообщения хранят начало данных сообщения. Остальные кодовые слова данных с
хранит только значение режима, а следующие девять кодовых слов данных первичного сообщения хранят начало данных сообщения. Остальные кодовые слова данных с ![]() и далее размещаются во вторичном сообщении, начиная с
и далее размещаются во вторичном сообщении, начиная с ![]() . В графе "Режимы 4, 5 и 6" таблицы H.1 указаны эти значения. Можно обнаружить, что кодовые слова первичного сообщения относятся к подмножеству коррекции ошибок
. В графе "Режимы 4, 5 и 6" таблицы H.1 указаны эти значения. Можно обнаружить, что кодовые слова первичного сообщения относятся к подмножеству коррекции ошибок ![]() , не зависимому от всех подмножеств вторичного сообщения. При необходимости кодовые слова [Pad] ([ЗАПОЛНИТЕЛЬ]) дополняют вторичное сообщение до
, не зависимому от всех подмножеств вторичного сообщения. При необходимости кодовые слова [Pad] ([ЗАПОЛНИТЕЛЬ]) дополняют вторичное сообщение до ![]() в режимах 4 и 6 или до
в режимах 4 и 6 или до ![]() в режиме 5.
в режиме 5.
Этап 3 - Добавление кодовых слов коррекции ошибок
a) Первичное сообщение
Независимо от режима символа, первичное сообщение всегда содержит 10 кодовых слов данных от ![]() до
до ![]() (или от
(или от ![]() до
до ![]() ) и 10 дополнительных кодовых слов исправления ошибки Рида-Соломона от
) и 10 дополнительных кодовых слов исправления ошибки Рида-Соломона от ![]() до
до ![]() (или от
(или от ![]() до
до ![]() ), которые вычисляют в соответствии с 4.10.1.
), которые вычисляют в соответствии с 4.10.1.
Хотя математика замкнутого поля Галуа GF(64) является неестественной по отношению к традиционной десятичной математике, этот пример будет продолжен для сравнения с другими компьютерными применениями. Если пользователь выбирает режим 4, последовательность кодовых слов данных в первичном сообщении от ![]() до
до ![]() представляется следующим образом:
представляется следующим образом:
[04, 13, 63, 01, 24, 09, 59, 03, 15, 04].
Это коэффициенты полинома в поле Галуа GF(64):
![]() .
.
Этот полином затем делится на порождающий полином (4.10.1):
![]()
с остатком от деления
![]() .
.
Эти 10 коэффициентов становятся для первичного сообщения кодовыми словами коррекции ошибок Рида-Соломона. Таким образом, вся последовательность кодовых слов первичного сообщения с ![]() по
по ![]() становится:
становится:
[04, 13, 63, 01, 24, 09, 59, 03, 15, 04, 50, 02, 42, 51, 53, 34, 22, 20, 02, 16].
b) Вторичное сообщение
Вторичное сообщение содержит 124 знака символа в символе MaxiCode в режимах 2, 3, 4 и 6 как 84 кодовых слова данных и 40 кодовых слов стандартной коррекции ошибок, а в режиме 5 как 68 кодовых слов данных и 56 кодовых слов расширенной коррекции ошибок. Во всех случаях кодирование Рида-Соломона разделено и высчитывается по двум чередующимся подмножествам: нечетным (![]() ) и четным (
) и четным (![]() ) знакам символа. В таблице H.1 четко указано это разделение.
) знакам символа. В таблице H.1 четко указано это разделение.
Пример с режимами 4, 5 или 6.
Данные для нечетного подмножества Рида-Соломона
![]() ,...,
,...,![]() =[05, 57, 49, 47, 08, 18, 59, 33,..., 33],
=[05, 57, 49, 47, 08, 18, 59, 33,..., 33],
а данные для четного подмножества Рида-Соломона:
![]() ,...,
,...,![]() =[47, 40, 57, 03, 01, 19, 41, 33,..., 33],
=[47, 40, 57, 03, 01, 19, 41, 33,..., 33],
где N равно 42 для стандартной коррекции ошибок и 34 - для расширенной коррекции ошибок.
Используя соответствующий порождающий полином из 4.10.2, можно вычислить с помощью деления и последующего сложения (62-N ) кодовые слова с исправлением ошибки Рида-Соломона для каждого подмножества. Для режима 4 полные результирующие подмножества являются следующими:
|
| |
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, | |
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, | |
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 02, | |
|
58, 06, 06, 39, 13, 63, 02, 30, 19, 19, 14, | |
|
19, 23, 17, 62, 08, 02, 23] | |
|
и | |
|
| |
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, | |
|
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, |
|
|
33, 33, 33, 33, 33, 33, 33, 33, 33, 01, 15, |
|
|
22, 28, 39, 17, 60, 05, 35, 35, 04, 08, 00, |
|
|
32, 51, 45, 63, 53, 61, 14]. |
Следует отметить, что несмотря на то, что эти два подмножества кодируются независимо, они полностью чередуются на протяжении всего вторичного сообщения, таким образом последнее нечетное кодовое слово коррекции ошибок ![]() заполняет последнюю позицию нечетного знака символа
заполняет последнюю позицию нечетного знака символа ![]() , аналогично
, аналогично ![]() заполняет
заполняет ![]() . Таким образом, в этом примере полная последовательность знаков символа вторичного сообщения становится следующей:
. Таким образом, в этом примере полная последовательность знаков символа вторичного сообщения становится следующей:
![]() ,···,
,···,![]() = [05, 47, 57, 40, 49, 57,..., 08, 53, 02, 61, 23, 14].
= [05, 47, 57, 40, 49, 57,..., 08, 53, 02, 61, 23, 14].
Этап 4 - Графическое кодирование
Результатом описанных этапов математического кодирования является обеспечение значений для всех 144 знаков символа в символе MaxiCode. Последний этап заключается в использовании графических компоновок на рисунках 4 и 5 для установления, в каком месте символа в действительности находятся 6 битов для каждого кодового слова. Биты кодовых слов со значениями 1 отображаются темными, а биты со значением 0 остаются светлыми. На рисунке H.1 изображен символ MaxiCode, полученный в данном примере кодирования, с использованием режима 4.

ПРИЛОЖЕНИЕ J
(рекомендуемое)
Практические рекомендации по печати
Контрольными размерами символа MaxiCode являются расстояния ![]() от центра крайнего левого модуля до центра крайнего правого модуля верхней и нижней строк (и каждой строки, состоящей из 30 модулей). Место расположения модуля вычисляют по формуле
от центра крайнего левого модуля до центра крайнего правого модуля верхней и нижней строк (и каждой строки, состоящей из 30 модулей). Место расположения модуля вычисляют по формуле
![]() .
.
![]() (среднее значение для допустимого диапазона длин
(среднее значение для допустимого диапазона длин ![]() ) равно 25,50 мм. Не все технологии печати могут обеспечить указанную номинальную длину и расстояния между центрами модулей (
) равно 25,50 мм. Не все технологии печати могут обеспечить указанную номинальную длину и расстояния между центрами модулей (![]() ). Диапазон достижимых длин
). Диапазон достижимых длин ![]() может быть определен с учетом возможностей технологий печати.
может быть определен с учетом возможностей технологий печати.
При разрешении 12 точек/мм и ширине модуля 10 пикселей ![]() равно 24,17 мм, что близко к наименьшему допустимому значению. При разрешении 7,57 точек/мм и ширине модуля 7 пикселей
равно 24,17 мм, что близко к наименьшему допустимому значению. При разрешении 7,57 точек/мм и ширине модуля 7 пикселей ![]() равно 26,86 мм, что близко к наибольшему допустимому значению. В 7.1 и 7.2 определены параметры для различных размеров пикселей.
равно 26,86 мм, что близко к наибольшему допустимому значению. В 7.1 и 7.2 определены параметры для различных размеров пикселей.
Программа вывода изображения допустимого шаблона поиска с указанным разрешением включена в [7].
J.1. 12 точек на 1 мм
При разрешении 12 точек/мм модуль должен быть создан в соответствии с рисунком J.1. Общая ширина модуля ![]() должна составлять 10 пикселей или 0,833 мм. Высота модуля
должна составлять 10 пикселей или 0,833 мм. Высота модуля ![]() должна быть 12 пикселей или 1,000 мм.
должна быть 12 пикселей или 1,000 мм.
Рисунок J.1 - Модуль MaxiCode, напечатанный с разрешением 12 точек/мм
Вложенная структура соседних модулей должна соответствовать шаблону, изображенному на рисунке J.2. Два изображенных квадрата не входят ни в один шестиугольник и не печатаются.
Рисунок J.2 - Вложенная структура модулей MaxiCode при разрешении 12 точек/мм
На рисунке J.3 изображен типичный шаблон поиска, созданный с разрешением 12 точек/мм.

Рисунок J.3 - Типичный шаблон поиска MaxiCode, напечатанный с разрешением 12 точек/мм
J.2 8 точек на миллиметр
При разрешении 8 точек/мм модуль должен быть создан, как показано на рисунке J.4. Общая ширина модуля ![]() должна составлять 7 пикселей или 0,875 мм. Высота модуля
должна составлять 7 пикселей или 0,875 мм. Высота модуля ![]() должна быть 8 пикселей или 1,000 мм.
должна быть 8 пикселей или 1,000 мм.
Рисунок J.4 - Модуль MaxiCode, напечатанный с разрешением 8 точек/мм
Вложенная структура соседних модулей должна соответствовать шаблону, изображенному на рисунке J.5. На рисунке J.5 четыре черных квадрата обозначают расположение пикселей, принадлежащих одновременно двум соседним шестиугольникам; эти места расположения будут напечатаны темными, если пиксели в обоих соседних шестиугольниках темные.
Рисунок J.5 - Вложенная структура модулей MaxiCode при разрешении 8 точек/мм
На рисунке J.6 представлен типичный шаблон поиска, созданный с разрешением 8 точек/мм.

Рисунок J.6 - Типичный шаблон поиска MaxiCode, напечатанный с разрешением 8 точек/мм
J.3 Общие правила для иных размеров пикселя
1) Значение ![]() должно быть в диапазоне от 24,00-27,00 мм, значение
должно быть в диапазоне от 24,00-27,00 мм, значение ![]() - в диапазоне 22,90-25,80 мм.
- в диапазоне 22,90-25,80 мм.
2) Значения ![]() (
(![]() в ряду) и
в ряду) и ![]() должны быть точными целочисленными значениями, кратными размеру пикселей.
должны быть точными целочисленными значениями, кратными размеру пикселей.
Примечание - В ряду ![]() должно быть равным
должно быть равным ![]() , но в результате вложения модулей может оказаться, что
, но в результате вложения модулей может оказаться, что ![]() имеет разные значения для расстояний между центрами модулей соседних строк. Например, при 8 точках/мм
имеет разные значения для расстояний между центрами модулей соседних строк. Например, при 8 точках/мм ![]() равно 0,875 мм (точное целочисленное кратное) в одной строке, но 0,839 мм и 0,901 мм между центрами модулей соседних строк.
равно 0,875 мм (точное целочисленное кратное) в одной строке, но 0,839 мм и 0,901 мм между центрами модулей соседних строк.
3) Расстояния между краями модулей ![]() и между центрами модулей в строке
и между центрами модулей в строке ![]() должны удовлетворять следующим равенствам:
должны удовлетворять следующим равенствам:
![]() ;
;![]() .
.
4) Расстояние по вертикали между центрами модулей ![]() определяют относительно
определяют относительно ![]() строки:
строки:
![]() .
.
Вычисленное значение ![]() должно быть округлено до кратного значения, ближайшего к номинальному размеру (в соответствии с таблицей 7 и 4.11.2).
должно быть округлено до кратного значения, ближайшего к номинальному размеру (в соответствии с таблицей 7 и 4.11.2).
5) Высоту модуля по вертикали определяют относительно ![]() :
:
![]() .
.
Вычисленное значение ![]() должно быть округлено до кратного значения, ближайшего к номинальному размеру (в соответствии с таблицей 7 и 4.11.2).
должно быть округлено до кратного значения, ближайшего к номинальному размеру (в соответствии с таблицей 7 и 4.11.2).
J.4 Определение шестиугольного шрифта для заданного точечного шага
1) Вычисляют общее число точек в ![]() (25,5 мм), например для 8 точек/мм - 204 точки;
(25,5 мм), например для 8 точек/мм - 204 точки;
2) делят полученное значение на 29 для определения количества точек в ![]() , например для 8 точек/мм - 7,034;
, например для 8 точек/мм - 7,034;
3) округляют значение до ближайшего целого числа. Полученное значение - ширина шестиугольника в точках, т.е. 7,034 превращается в 7 точек;
4) вычисляют ![]() и
и ![]() в точках, используя
в точках, используя ![]() , равное
, равное ![]() из вышеуказанного, например,
из вышеуказанного, например, ![]() =1/1547·7=8,0829,
=1/1547·7=8,0829, ![]() =0,866·7=6,062;
=0,866·7=6,062;
5) округляют значения до ближайших целых чисел. Полученный результат является соответственно высотой шестиугольника и расстоянием между строками. Разность этих значений соответствует перекрытию строк, например, для 8 точек/мм ![]() =8,
=8, ![]() =6 и перекрытие
=6 и перекрытие ![]() =2;
=2;
6) вычисляют ![]() и
и ![]() по заданным
по заданным ![]() ,
, ![]() и
и ![]() и определяют, находятся ли они в диапазоне допустимых значений, например, для 8 точек/мм
и определяют, находятся ли они в диапазоне допустимых значений, например, для 8 точек/мм ![]() =7·29/8=25,375,
=7·29/8=25,375, ![]() =6·32/8=24,00. Оба значения находятся в диапазоне допустимых значений;
=6·32/8=24,00. Оба значения находятся в диапазоне допустимых значений;
7) если значения находятся за пределами допуска, тогда ![]() округляют иначе, чем на этапе 3 (следующее целое значение) и повторяют этапы с 4-го по 6-й. Если
округляют иначе, чем на этапе 3 (следующее целое значение) и повторяют этапы с 4-го по 6-й. Если ![]() или
или ![]() все еще находятся вне допуска, то может оказаться невозможным напечатать символ MaxiCode при заданном точечном шаге. Если оба размера находятся в пределах допуска, продолжают процедуру с этапа 8;
все еще находятся вне допуска, то может оказаться невозможным напечатать символ MaxiCode при заданном точечном шаге. Если оба размера находятся в пределах допуска, продолжают процедуру с этапа 8;
8) для заполнения шрифта выкладывают строку из трех прилежащих друг к другу шестиугольников. Вначале используют одну строку и один столбец точек, проходящих через центр каждого шестиугольника. Центры шестиугольников находятся в точках пересечения строк и столбцов, например, для 8 точек/мм получится горизонтальная линия из 21 точки с тремя столбцами по 8 точек каждая, проходящие через точки 4, 11 и 18;
9) аналогично создают вторую строку из двух соседних шестиугольников. Эта строка будет смещена от первой на ![]() /2 точек вправо и на
/2 точек вправо и на ![]() точек вниз. Например, для 8 точек/мм строка будет представлять собой горизонтальную линию шириной в 14 точек и высотой в 2 столбца по 8 точек, проходящую через точки 4 и 11. Следовательно, вторая строка будет расположена на 3 точки правее и на 6 точек ниже первой строки (рисунок J.7a);
точек вниз. Например, для 8 точек/мм строка будет представлять собой горизонтальную линию шириной в 14 точек и высотой в 2 столбца по 8 точек, проходящую через точки 4 и 11. Следовательно, вторая строка будет расположена на 3 точки правее и на 6 точек ниже первой строки (рисунок J.7a);
10) заполнение шестиугольников начинают из центра, заполняя одинаковые точки в каждом из 5 шестиугольников. Повторяют процедуру, сохраняя каждый шестиугольник идентичным и симметричным (рисунок J.7b);
11) задача состоит в том, чтобы как можно полнее заполнить пространство шестиугольника, оставляя интервалы между соседними шестиугольниками. Интервал между шестиугольниками сохраняется благодаря тому, что пространство вокруг шестиугольника, где это возможно, заполняется периферийными пикселями неоднородно (рисунок J.7с). Необходимо удалить некоторые пиксели из первоначальных линий для сохранения интервала (рисунок J.7d). Число оставленных белыми печатных пикселей между черными шестиугольниками зависит от разрешающей способности принтера. Основываясь на допуске, заданном в 4.11.3, предлагаются следующие интервалы:
|
8 точек/мм (200 точек/дюйм) |
|
1 пиксель |
|
12 точек/мм (300 точек/дюйм) |
|
от 1-го до 2-х пикселей |
|
16 точек/мм (400 точек/дюйм) |
|
2 пикселя |
|
20 точек/мм (500 точек/дюйм) |
|
от 2-го до 3-х пикселей |
|
24 точки/мм (600 точек/дюйм) |
|
3 пикселя |
а - размещение строк (перечисление 9), b - заполнение шестиугольников из центра (перечисление 10),
с - полное заполнение пространства шестиугольника (перечисление 11), d - заполнение после удаления
пикселей для сохранения интервала между шестиугольниками (перечисление 11)
Рисунок J. 7 - Создание шрифта шестиугольников
ПРИЛОЖЕНИЕ К
(справочное)
Возможности автоматического распознавания
MaxiCode может быть считан соответствующим образом запрограммированными декодерами, разработанными для автоматического распознавания MaxiCode от других символик. Запрограммированное соответствующим образом устройство считывания MaxiCode не декодирует ни одну из следующих символик как действительный символ MaxiCode, однако представления, подобные коротким линейным символам, могут встречаться в любых матричных символах, включая MaxiCode. Таким образом символы MaxiCode совместимы при автоматическом распознавании с символами следующих символик:
Линейные символики:
Codabar (Кодабар)
Code 11 (Код 11)
Code 39 (Код 39)
Code 93 (Код 93)
Code 128 (Код 128)
Interleaved 2 of 5 (2 из 5 чередующийся)
EAN/UPC (ЕАН/ЮПиСи)
Telepen (Телепен)
Двумерные символики - многострочные:
CODABLOCK A F (Кодаблок А и Ф)
Code 16 К (Код 16К)
Code 49 (Код 49)
PDF417 (ПДФ417)
Двумерные символики - матричные
Code One (Код один)
Data Matrix (Дата матрикс)
Для достижения максимальной надежности считывания набор символик, распознаваемых декодером, должен быть ограничен потребностями конкретного применения.
ПРИЛОЖЕНИЕ L
(справочное)
Практические методы управления процессом
Инструментальные средства и процедуры, используемые на практике для контроля и управления процессом создания символов MaxiCode, не проверяют качества печати созданных символов (метод из 4.12 и приложение С - требуемый метод для оценки качества печати символа), а по отдельности и вместе показывают, создает ли процесс печати символов работоспособный символ.
L.1 Контраст символа
Большинство верификаторов линейных штриховых кодов имеют как режим рефлектометра, так и режим вывода изображения профилей отражения при сканировании и/или показывают контраст символа ([6]) при недекодируемом сканировании. В общем случае контрасты символа, полученные при считываниях с использованием апертуры 0,25 мм и длины волны 660 нм (установленные значения как контраста символа SC и разности коэффициентов отражения в точках с наибольшим и наименьшим значениями коэффициента отражения в профиле отражения при сканировании символа, так и разности между максимальным и минимальным показаниями рефлектометра), хорошо коррелируют с контрастом символа, полученным из изображения. В частности, эти считывания используют для того, чтобы проверить, намного ли контраст символа превышает минимум, допустимый для предполагаемого класса качества символа.
L.2 Размер символа
Изображение накладного трафарета (рисунок L.1) позволяет визуально проверить:
1) изменения при печати шаблона поиска,
2) размещение шаблонов ориентации,
3) общий размер символа.

Рисунок L.1 - Накладной трафарет качества печати MaxiCode
Примечание - Данный трафарет (на прозрачной подложке) (рисунок L.1), любезно предоставленный PSC Incorporated и United Parcel Service и опубликованный в [7], приведен в настоящем стандарте с целью пояснения текста данного документа. Он защищен патентами, включая US D374630 и 5,552,593 © 1996 PSC Inc. Указанный трафарет можно заказать в AIM Inc., в том числе через ААИ ЮНИСКАН/АIМ РОССИЯ.
L.2.1 Проверка изменения печати
Центральный кольцевой шаблон создан таким образом, что он должен точно накрывать на левой стороне, обозначенной "Уменьшение", все допустимые кольца поиска, кроме недопустимо узких, на правой стороне, обозначенной "Увеличение", все допустимые кольца поиска, кроме недопустимо широких. При размещении трафарета точно по центру проверяемого символа слева не должны быть видны светлые области (в противном случае это означает, что кольца слишком узкие или неправильного размера), но некоторое белое пространство должно быть видно справа (в противном случае это означает, что кольца слишком широкие).
L.2.2 Проверка размещения шаблонов поиска и ориентации
Одиннадцать шестиугольников, обозначенных "шестиугольники ориентации", изображены вокруг шаблона поиска и являются местоположениями темных модулей в шаблонах ориентации. Когда трафарет располагается строго по центру на шаблоне поиска проверяемого символа с правильным выравниванием символа, темные модули должны заполнять или располагаться по центру каждого изображенного шестиугольника. Систематическое смещение показывает неправильное размещение шаблона поиска или неправильный размер сетки данных, в то время как один или несколько пропущенных темных модулей ориентации означают неправильную конструкцию символа. Темные шестиугольники ориентации могут быть единообразно смещены к центру или от центра, если символ приближается соответственно к своим минимальным или максимальным размерам так, чтобы шестиугольники ориентации заполняли шестиугольники трафарета только частично.
L.2.3 Проверка общего размера символа
Две внешние границы (пунктирная, обозначенная "Минимальный размер", и сплошная, обозначенная "Максимальный размер"), обозначают допустимый диапазон масштабирования символа MaxiCode. При расположении трафарета по центру шаблона поиска крайняя наружная строка модулей данных символа должна достигать штриховой границы, но не должна заходить за сплошную границу, в противном случае это означает, что символ имеет неправильный размер.
Примечание - Шаблон поиска в символе MaxiCode расположен не точно по горизонтали, а также высота и ширина символа не точно равны друг другу, поэтому проверка обеспечивается только в том случае, если тестируемый символ правильно ориентирован и его верхний край соответствует верхнему краю трафарета.
L.3 Искажение символа
Двумерные матричные символики восприимчивы к ошибкам, вызванным местными искажениями матричной сетки. Одной из наиболее распространенных причин подобных искажений является неоднородное движение этикетки в процессе печати, поэтому рекомендуется оперативно визуально проверить наличие ошибок такого типа следующим способом.
Как показано на рисунке L.2, шаблон в виде "застежки молнии" может быть напечатан рядом с символом по направлению печати. В правой части рисунка содержится увеличенное представление участка этого шаблона "молнии". При снижении скорости этикетки при печати в любой точке печати данный участок шаблона "молнии" станет темнее. Наоборот, при увеличении скорости этикетки при печати в любой точке данный участок шаблона "молнии" станет светлее. Таким образом легко обнаружить символы, имеющие локальную неоднородность.

Рисунок L.2 - Символ MaxiCode с шаблоном "молния" и с увеличенным представлением шаблона "молния"
L.4 Изменения печати и дефекты
Постоянная визуальная проверка образцов символов может обнаружить два важных параметра в процессе печати. Первый заключается в том, что темные модули данных должны заполнять только 75% отведенной шестиугольной области и фактически не касаются прилежащих темных модулей. Если соседние темные шестиугольники сливаются в группы (как это происходит в большинстве других матричных символик), то увеличение печати на самом деле фактически затрудняет считывание.
Второй заключается в том, что кольца шаблона поиска всегда должны быть полностью темными и светлыми и однородной толщины. Неисправности механизма печати, которые могут вызвать дефекты в виде светлых или темных полос, проходящих через символ, должны быть заметными, если они заходят на шаблон поиска. Такие систематические неисправности в процессе печати должны быть исправлены.
ПРИЛОЖЕНИЕ М
(справочное)
Наименования и обозначения управляющих знаков
В таблице М.1 приведено соответствие международных и русских наименований и обозначений управляющих знаков символики, приведенных в настоящем стандарте.
Таблица M.1 - Соответствие международных и русских наименований и обозначений управляющих знаков символики (Symbology Control Characters)
|
Обозначения знака |
Наименование знака | ||
|
международное |
русское |
международное |
русское |
|
[Latch A] |
[ФИКСАТОР А] |
Latch Character A |
Знак ФИКСАТОР А |
|
[Latch В] |
[ФИКСАТОР В] |
Latch Character В |
Знак ФИКСАТОР В |
|
[Shift A] |
[РЕГИСТР А] |
Shift Character A |
Знак РЕГИСТР А |
|
[Shift В] |
[РЕГИСТР В] |
Shift Character В |
Знак РЕГИСТР В |
|
[Shift С] |
[РЕГИСТР С] |
Shift Character С |
Знак РЕГИСТР С |
|
[Shift D] |
[РЕГИСТР D] |
Shift Character D |
Знак РЕГИСТР D |
|
[Shift E] |
[РЕГИСТР E] |
Shift Character E |
Знак РЕГИСТР Е |
|
[2 Shift A] |
[2 РЕГИСТР А] |
Double Shift Character |
Знак РЕГИСТР НА ДВА |
|
[3 Shift A] |
[3 РЕГИСТР А] |
Triple Shift Character |
Знак РЕГИСТР НА ТРИ |
|
[NS] |
[ЦР] |
Numeric Shift Character |
Знак ЦИФРОВОЙ РЕГИСТР |
|
[Lock-In C] |
[БЛОКИРОВКА С] |
Lock-In Character С |
Знак БЛОКИРОВКА С |
|
[Lock-In D] |
[БЛОКИPOBКA D] |
Lock-In Character D |
Знак БЛОКИРОВКА D |
|
[Lock-In E] |
[БЛОКИРОВКА E] |
Lock-In Character E |
Знак БЛОКИРОВКА Е |
|
[ECI] |
[ИРК] |
Extended Channel Interpretation Character |
Знак интерпретации расширенного канала |
|
[Pad] |
[ЗАПОЛНИТЕЛЬ] |
Pad Character |
Знак ЗАПОЛНИТЕЛЬ |
В таблице М.2 приведено соответствие международных и русских наименований и обозначений управляющих знаков КОИ-7 (КОИ-8), указанных в настоящем стандарте.
Таблица М.2 - Знаки КОИ-7 (КОИ-8)
|
Обозначения знака |
Наименование знака | ||
|
международное |
русское |
международное |
русское |
|
NUL |
ПУС |
NULL |
ПУСТО |
|
SOH |
НЗ |
START OF HEADING |
НАЧАЛО ЗАГОЛОВКА |
|
STX |
HT |
START OF TEXT |
НАЧАЛО ТЕКСТА |
|
ETX |
КТ |
END OF TEXT |
КОНЕЦ ТЕКСТА |
|
EOT |
КП |
END OF TRANSMISSION |
КОНЕЦ ПЕРЕДАЧИ |
|
ENQ |
КТМ |
ENQUIRY |
КТО ТАМ? |
|
ACK |
ДА |
ACKNOWLEDGE |
ПОДТВЕРЖДЕНИЕ |
|
BEL |
ЗВ |
BELL |
ЗВОНОК |
|
BS |
ВШ |
BACKSPACE |
ВОЗВРАТ НА ШАГ |
|
HT |
ГТ |
HORIZONTAL TABULATION |
ГОРИЗОНТАЛЬНАЯ ТАБУЛЯЦИЯ |
|
LF |
ПС |
LINE FEED |
ПЕРЕВОД СТРЕЛКИ |
|
VT |
ВТ |
VERTICAL TABULATION |
ВЕРТИКАЛЬНАЯ ТАБУЛЯЦИЯ |
|
FF |
ПФ |
FORM FEED |
ПЕРЕВОД ФОРМАТА |
|
CR |
ВК |
CARRIAGE RETURN |
ВОЗВРАТ КАРЕТКИ |
|
SO |
ВЫХ |
SHIFT-OUT |
ВЫХОД |
|
SI |
ВХ |
SHIFT-IN |
ВХОД |
|
DLE |
AP1 |
DATA LINK ESCAPE |
АВТОРЕГИСТР ОДИН |
|
DC1 |
СУ1 |
DEVICE CONTROL ONE |
СИМВОЛ УСТРОЙСТВА ОДИН |
|
DC2 |
СУ2 |
DEVICE CONTROL TWO |
СИМВОЛ УСТРОЙСТВА ДВА |
|
DC3 |
СУЗ |
DEVICE CONTROL THREE |
СИМВОЛ УСТРОЙСТВА ТРИ |
|
DC4 |
СУ4 |
DEVICE CONTROL FOUR |
СИМВОЛ УСТРОЙСТВА ЧЕТЫРЕ |
|
NAK |
НЕТ |
NEGATIVE ACKNOWLEDGE |
ОТРИЦАНИЕ |
|
SYN |
СИН |
SYNCHRONOUS IDLE |
СИНХРОНИЗАЦИЯ |
|
ETB |
КБ |
END OF TRANSMISSION BLOCK |
КОНЕЦ БЛОКА |
|
CAN |
АН |
CANCEL |
АННУЛИРОВАНИЕ |
|
EM |
КН |
END OF MEDIUM |
КОНЕЦ НОСИТЕЛЯ |
|
SUB |
ЗМ |
SUBSTITUTE CHARACTER |
ЗАМЕНА СИМВОЛА |
|
ESC |
АР2 |
ESCAPE |
АВТОРЕГИСТР ДВА |
|
FS |
РФ |
FILE SEPARATOR |
РАЗДЕЛИТЕЛЬ ФАЙЛОВ |
|
GS |
РГ |
GROUP SEPARATOR |
РАЗДЕЛИТЕЛЬ ГРУПП |
|
RS |
РЗ |
RECORD SEPARATOR |
РАЗДЕЛИТЕЛЬ ЗАПИСЕЙ |
|
US |
РЭ |
UNIT SEPARATOR |
РАЗДЕЛИТЕЛЬ ЭЛЕМЕНТОВ |
|
DEL |
ЗБ |
DELETE |
ЗАБОЙ |
|
NBSP |
НПР |
NO-BREAK SPACE |
НЕПРЕРЫВАЮЩИЙ ПРОБЕЛ |
|
SHY |
ГД |
SOFT HYPHEN |
ГИБКИЙ ДЕФИС |
|
Примечания | |||
ПРИЛОЖЕНИЕ N
(справочное)
Сведения о наборе знаков по ИСО 8859-5
В таблице N.1 представлена вторая половина набора 8-битных однобайтных кодированных знаков по ИСО 8859-5, содержащая буквы кирилловского алфавита (с указанием десятичных значений байтов от 160 до 255 включительно).
Таблица N.1 - Вторая половина набора знаков по ИСО 8859-5
|
NBSP 160 |
Ё |
Ђ |
Ѓ |
Є |
S |
I |
Ї |
J |
Љ |
Њ |
Ћ |
|
Ќ |
SHY |
Ў |
Џ |
А |
Б |
В |
Г |
Д |
Е |
Ж |
З |
|
И |
Й |
К |
Л |
М |
Н |
О |
П |
|
С |
Т |
У |
|
Ф |
X |
Ц |
Ч |
Ш |
Щ |
Ъ |
Ы |
Ь |
Э |
Ю |
Я |
|
а |
б |
в |
г |
д |
е |
ж |
з |
и |
й |
к |
л |
|
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
|
ш |
щ |
ъ |
ы |
ь |
э |
ю |
я |
№ |
ё |
ђ |
ѓ |
|
є |
s |
i |
ї |
ј |
љ |
њ |
ћ |
ќ |
§ |
ў |
џ |
|
Примечание - Международные и русские наименования знаков NBSP, SHY - в соответствии с приложением М. | |||||||||||
ПРИЛОЖЕНИЕ Р
(справочное)
Библиография
[1] АНСИ Х 3.4 Наборы кодированных знаков. 7-битный код американского национального стандарта для обмена информацией (7-битный ASCII)
[2] Техническая спецификация АИМ Интернешнл. Интерпретации расширенного канала - Часть 1: Идентификационные схемы и протокол
[3] АИМ США Руководство для режима 0 для MaxiCode
[4] АНСИ Х3.182 Руководство по оценке качества печати штриховых кодов
[5] АИМ США Дискета разработчиков MaxiCode
[6] EH 796-96 Штриховое кодирование. Идентификаторы символик
[7] Техническая спецификация АИМ Интернешнл. Международная спецификация символики MaxiCode
Текст документа сверен по:
официальное издание
М.: ИПК Издательство стандартов, 2001
Личный кабинет:
доступно после авторизации Кубанский блогер Каграманов рассказал в «Шоу Воли» о хейте в...
Кубанский блогер Каграманов рассказал в «Шоу Воли» о хейте в...  Создайте свой интернет-магазин на новой платформе ReadyScript
Создайте свой интернет-магазин на новой платформе ReadyScript  Хостинг, домены, VPS/VDS, размещение серверов
Хостинг, домены, VPS/VDS, размещение серверов
© 2007-2025 ООО «РуФокс»
о проекте
вакансии
хостинг
создание сайтов
реклама на сайте
наши партнеры
сообщить об ошибке